 |
| PLAYA DEL MÉDANO, MONTAÑA ROJA Y LA LUNA EN UNA NOCHE ESTRELLADA Y LIMPIA DE VERANO EN EL SUR DE TENERIFE, GRANADILLA DE ABONA, TENERIFE. |
Cuestión de etimología: 'serializar' significa 'poner en serie una colección de elementos, uno detrás del otro'. Y esto es algo que los bytes hacen muy, pero que muy bien. Es uno de los fuertes de ser un bit. Y de hecho, esta capacidad de representar cosas colocándose en una cantidad determinada uno detrás del otro (en serie) es lo que hace, precisamente, que esto de la Informática funcione. ¿Por qué? Entre otros muchos aspectos, por uno que nos interesa en particular y que nos aproxima al concepto que queremos manejar aquí: porque gracias a los bytes es posible DECONSTRUIR en origen un objeto (fichero, archivo del tipo que sea, información, etc.), hacerlo pasar y transmitirlo de un punto a otro con independencia de la distancia por un canal etéreo como las ondas o increíblemente angosto como un filamento de cobre, y RECONSTRUIRLO a la perfección, sin pérdida, tal cual, en destino, con un gasto irrisorio de energía y un altísimo nivel de eficacia.
Lo cual, mire usted por dónde, viene de perlas para transmitir archivos de un sitio a otro de una manera sencilla, eficaz, sin apenas gasto energético y con garantía de calidad. ¿Quién da más?
Podemos poner de ejemplo la cláusula BLOB en lenguaje SQL para la creación y gestión de bases de datos. BLOB transforma (deconstruye) un archivo gráfico cualquiera en datos de tipo binario (serie de bytes) y lo inserta como tal en un campo de una tabla de datos que hayamos construido, dado que las bases de datos no almacenan ficheros. Si queremos recuperar el archivo gráfico para verlo, por ejemplo, en pantalla y posteriormente imprimirlo para regalárselo a un familiar, tendremos que transformar (reconstruir) la serie de bytes en que la cláusula BLOB transformó previamente al mencionado archivo a sus elementos originales, en un proceso inverso.
Podemos poner de ejemplo la cláusula BLOB en lenguaje SQL para la creación y gestión de bases de datos. BLOB transforma (deconstruye) un archivo gráfico cualquiera en datos de tipo binario (serie de bytes) y lo inserta como tal en un campo de una tabla de datos que hayamos construido, dado que las bases de datos no almacenan ficheros. Si queremos recuperar el archivo gráfico para verlo, por ejemplo, en pantalla y posteriormente imprimirlo para regalárselo a un familiar, tendremos que transformar (reconstruir) la serie de bytes en que la cláusula BLOB transformó previamente al mencionado archivo a sus elementos originales, en un proceso inverso.
Pues bien, el proceso para lograr esto en los lenguajes de programación se llama SERIALIZACIÓN.

Centrándonos en Python, podemos serializar objetos (prácticamente, cualquier objeto Python) a través de dos librerías incluidas de serie en la biblioteca estándar: se trata de los módulos Pickle y Shelve.
La razón que justifica en mayor medida la serialización de un objeto es la EXTERNALIZACIÓN, es decir, almacenar en un fichero externo al propio Python, un objeto Python cualquiera, como un diccionario, una lista, un dato o valor del tipo que sea, una combinación de varios, etc. Para que esto sea posible es necesario "binarizar" (convertir a código binario, bytes) la información a través de las librerías que hemos mencionado, lo que nos permitirá, a parte de preservar los datos (persistencia de la información), distribuirlos al exterior, por ejemplo, a través de internet, para lo que es necesario, como ya sabemos y explicamos al comienzo del capítulo, que los datos que vayamos a distribuir se hayan traducido previamente a código binario y recuperar en destino esa misma información aplicando el proceso inverso: traducir de binario al lenguaje que entiende e interpreta Python para que el usuario pueda acceder a ella.
 COMO YO LO PRUEBO TODO (SOBRE TODO CUANDO TENGO HAMBRE) ME HE PUESTO A INVESTIGAR QUÉ OBJETOS PROPIOS DE PYTHON PODEMOS SERIALIZAR SIN PROBLEMAS, Y HE ENCONTRADO QUE SON ESTOS:
COMO YO LO PRUEBO TODO (SOBRE TODO CUANDO TENGO HAMBRE) ME HE PUESTO A INVESTIGAR QUÉ OBJETOS PROPIOS DE PYTHON PODEMOS SERIALIZAR SIN PROBLEMAS, Y HE ENCONTRADO QUE SON ESTOS:
➧ LOS QUE TOMAN VALORES True, False y None.
➧ LOS NÚMEROS COMPLEJOS, ENTEROS Y DECIMALES.
➧ BYTES, CADENAS DE BYTES Y CADENAS DE TEXTO.
➧COLECCIONES COMO CONJUNTOS, LISTAS, TUPLAS Y DICCIONARIOS QUE ALMACENEN DATOS COMO LOS RECOGIDOS MÁS ARRIBA.
➧CLASES MODELIZADAS POR EL PROGRAMADOR CON ELEMENTOS MENCIONADOS CON ANTERIORIDAD.
➧MÓDULOS.


La razón que justifica en mayor medida la serialización de un objeto es la EXTERNALIZACIÓN, es decir, almacenar en un fichero externo al propio Python, un objeto Python cualquiera, como un diccionario, una lista, un dato o valor del tipo que sea, una combinación de varios, etc. Para que esto sea posible es necesario "binarizar" (convertir a código binario, bytes) la información a través de las librerías que hemos mencionado, lo que nos permitirá, a parte de preservar los datos (persistencia de la información), distribuirlos al exterior, por ejemplo, a través de internet, para lo que es necesario, como ya sabemos y explicamos al comienzo del capítulo, que los datos que vayamos a distribuir se hayan traducido previamente a código binario y recuperar en destino esa misma información aplicando el proceso inverso: traducir de binario al lenguaje que entiende e interpreta Python para que el usuario pueda acceder a ella.

➧ LOS QUE TOMAN VALORES True, False y None.
➧ LOS NÚMEROS COMPLEJOS, ENTEROS Y DECIMALES.
➧ BYTES, CADENAS DE BYTES Y CADENAS DE TEXTO.
➧COLECCIONES COMO CONJUNTOS, LISTAS, TUPLAS Y DICCIONARIOS QUE ALMACENEN DATOS COMO LOS RECOGIDOS MÁS ARRIBA.
➧CLASES MODELIZADAS POR EL PROGRAMADOR CON ELEMENTOS MENCIONADOS CON ANTERIORIDAD.
➧MÓDULOS.
PICKLE:
Vamos a empezar con el módulo pickle de la librería estándar de Python. Se trata de la librería por antonomasia para efectuar este proceso de "binarización" y "desbinarización" de objetos Python. Y tanto es así que, fijémonos, en Python se denomina pickling al procedimiento por el cual se transforma un objeto cualquiera en una secuencia de bytes (sí, sí, la serialización) mientras que al proceso inverso se le denomina unplickling.
Si nos fijamos, hablamos siempre de dos procesos: uno conversión de objetos a binarios → pickling, y su complementario → unplickling. Y esto tiene su traducción en que los dos métodos principales y, realmente, casi los únicos que realmente nos hacen falta, son dump() y load().
Veamos cómo funcionan.
- dump() genera precisamente el proceso de pickling al producir un proceso de volcado del objeto Python a un archivo binario (bytes) externo al programa.
- load() ejecuta el proceso complementario de unplickling y traduce el archivo binario externo a objeto Python.


Como vemos, lo primero es la importación de la biblioteca, que bien podemos hacerlo de manera absoluta. A continuación tenemos el objeto Python que queremos transformar en secuencia binaria para su externalización, en este caso, una simple lista (colección de datos de tipo secuencia) de sabrosísimas frutas de las que nos venden en el súper de la esquina.
En la siguiente línea de código creamos el archivo externo donde vamos a volcar nuestra lista de frutas una vez la hayamos convertido a objeto binario. Para ello declaramos una variable: binaryfile, a la que asignamos el resultado de la ejecución de la función integrada open() que, como vemos, debe llevar dos argumentos: la ruta (path) donde vamos a crear el archivo, en este caso, el escritorio, y el nombre que llevará el archivo, justo a continuación de la última barra (slash), en el ejemplo, frutas; y el modo (mode) en que vamos a escribir. Como va a ser en binario, pasamos "wb" de writing binary como argumento.
Y ahora que tenemos nuestro fichero externo preparado para recibir nuestra lista de frutas con los renglones abiertos, pasamos a hacer magia:
Llamamos a la librería, pickle, y por la sintaxis del punto, de la librería llamamos a su vez al método dump(), que es el que nos interesa. Nuestro método dump() lleva dos parámetros: primero, dónde vamos a volcar los datos binarios (el pickling propiamente dicho); y segundo, qué objeto vamos a convertir en binario. Así pues, pasamos a dump() los siguientes argumentos: el nombre del fichero, binaryfile, y la variable que almacena nuestra lista de frutas, frutas, respectivamente.
Con esto ya hemos completado la serialización. ¡Hurra!
Ahora sólo resta cerrar el proceso de apertura de archivo, dado que no vamos a operar más, al menos de momento, en él tal y como nos recomienda Python para no malgastar recursos de memoria. Para hacerlo tan sólo llamamos al método close() que adjuntamos de nuevo por la sintaxis del punto a la variable que almacena al archivo externo, binaryfile.
La última línea de código es opcional. Sirve también para no almacenar archivos innecesarios en la memoria del programa, y para ello usamos la declaración del (de delete, "borrar", "eliminar") con el nombre del fichero, binaryfile.
Si ahora nos fijamos en la captura de pantalla, por el lado izquierdo, vemos dos ficheros sobre el escritorio con el nombre de frutas. El de la parte superior es el fichero binario (lo reconoceremos porque el icono representa un folio en blanco, sin líneas) mientras que el de la parte inferior es un texto plano, con extensión .txt (frutas.txt), con un icono que representa un folio rayado, señalando que puede ser leído por un editor de texto cualquiera, como el mismo bloc de notas, o similares.
 YA TENEMOS NUESTRO FICHERO BINARIO EXTERNALIZADO CON EL MÉTODO dump(), ESTO ES, ¡HEMOS HECHO PICKLING! VAMOS AHORA A VER SI SOMOS CAPACES DE REVERTIR EL PROCESO, VAMOS, HACERNOS UN UNPLICKING COMO UNA CASA, Y RECUPERAR LOS DATOS BINARIZADOS CON EL MÉTODO load().
YA TENEMOS NUESTRO FICHERO BINARIO EXTERNALIZADO CON EL MÉTODO dump(), ESTO ES, ¡HEMOS HECHO PICKLING! VAMOS AHORA A VER SI SOMOS CAPACES DE REVERTIR EL PROCESO, VAMOS, HACERNOS UN UNPLICKING COMO UNA CASA, Y RECUPERAR LOS DATOS BINARIZADOS CON EL MÉTODO load().
En la siguiente línea de código creamos el archivo externo donde vamos a volcar nuestra lista de frutas una vez la hayamos convertido a objeto binario. Para ello declaramos una variable: binaryfile, a la que asignamos el resultado de la ejecución de la función integrada open() que, como vemos, debe llevar dos argumentos: la ruta (path) donde vamos a crear el archivo, en este caso, el escritorio, y el nombre que llevará el archivo, justo a continuación de la última barra (slash), en el ejemplo, frutas; y el modo (mode) en que vamos a escribir. Como va a ser en binario, pasamos "wb" de writing binary como argumento.
Y ahora que tenemos nuestro fichero externo preparado para recibir nuestra lista de frutas con los renglones abiertos, pasamos a hacer magia:
Llamamos a la librería, pickle, y por la sintaxis del punto, de la librería llamamos a su vez al método dump(), que es el que nos interesa. Nuestro método dump() lleva dos parámetros: primero, dónde vamos a volcar los datos binarios (el pickling propiamente dicho); y segundo, qué objeto vamos a convertir en binario. Así pues, pasamos a dump() los siguientes argumentos: el nombre del fichero, binaryfile, y la variable que almacena nuestra lista de frutas, frutas, respectivamente.
Con esto ya hemos completado la serialización. ¡Hurra!
Ahora sólo resta cerrar el proceso de apertura de archivo, dado que no vamos a operar más, al menos de momento, en él tal y como nos recomienda Python para no malgastar recursos de memoria. Para hacerlo tan sólo llamamos al método close() que adjuntamos de nuevo por la sintaxis del punto a la variable que almacena al archivo externo, binaryfile.
La última línea de código es opcional. Sirve también para no almacenar archivos innecesarios en la memoria del programa, y para ello usamos la declaración del (de delete, "borrar", "eliminar") con el nombre del fichero, binaryfile.
Si ahora nos fijamos en la captura de pantalla, por el lado izquierdo, vemos dos ficheros sobre el escritorio con el nombre de frutas. El de la parte superior es el fichero binario (lo reconoceremos porque el icono representa un folio en blanco, sin líneas) mientras que el de la parte inferior es un texto plano, con extensión .txt (frutas.txt), con un icono que representa un folio rayado, señalando que puede ser leído por un editor de texto cualquiera, como el mismo bloc de notas, o similares.
 |
| PEQUEÑO ORATORIO EN ALGÚN LUGAR DE LAS CAÑADAS DEL TEIDE, BAJO LA LUZ TEMPLADA DEL ATARDECER. TENERIFE. |

Como podemos ver, en 1 mostramos el texto ininteligible, o casi, que resulta de abrir el fichero binario con el bloc de notas. Rarito, rarito.
Pues bueno, en 2 procedemos a realizar el proceso inverso al anterior.
De nuevo hacemos una importación absoluta de la librería pickle y declaramos una variable, en este caso, readbinaryfile, a la que asignaremos el resultado de la ejecución de la función integrada open() que, de nuevo, llevará dos parámetros, como debe ser: la ruta, (path), con la ubicación y el nombre del fichero del que vamos a traducir los datos binarios; y el modo, (mode), en este caso, de lectura binaria. Así pues, los argumentos con los que concretamos los parámetros de la función son: "C:/Users/Jose/Desktop/frutas", sin extensión puesto que el método load() buscará por defecto cualquier archivo binario que se encuentre en esa ruta; y "rb", de reading binary, respectivamente.
Declararemos ahora una nueva variable, nuevalistafrutas, que almacenará el resultado de la ejecución del método load() de pickle que se aplicará al archivo que le pasemos como argumento, como ya sabemos, el que tenemos almacenado en la variable readbinaryfile.
Con esto, ya hemos traducido a "lenguaje humano" nuestro fichero binario frutas y, con una simple llamada a print(), ¡oh maravilla!, podremos leer sin problemas la lista de frutas original.

Pues bueno, en 2 procedemos a realizar el proceso inverso al anterior.
De nuevo hacemos una importación absoluta de la librería pickle y declaramos una variable, en este caso, readbinaryfile, a la que asignaremos el resultado de la ejecución de la función integrada open() que, de nuevo, llevará dos parámetros, como debe ser: la ruta, (path), con la ubicación y el nombre del fichero del que vamos a traducir los datos binarios; y el modo, (mode), en este caso, de lectura binaria. Así pues, los argumentos con los que concretamos los parámetros de la función son: "C:/Users/Jose/Desktop/frutas", sin extensión puesto que el método load() buscará por defecto cualquier archivo binario que se encuentre en esa ruta; y "rb", de reading binary, respectivamente.
Declararemos ahora una nueva variable, nuevalistafrutas, que almacenará el resultado de la ejecución del método load() de pickle que se aplicará al archivo que le pasemos como argumento, como ya sabemos, el que tenemos almacenado en la variable readbinaryfile.
Con esto, ya hemos traducido a "lenguaje humano" nuestro fichero binario frutas y, con una simple llamada a print(), ¡oh maravilla!, podremos leer sin problemas la lista de frutas original.

Como en este blog somos atrevidos, vamos a comprobar cómo funciona la serialización con objetos Python más complejos, como una clase, por ejemplo, aún a pesar de que no hemos empezado a estudiarlas. No nos fijemos en la estructura sintáctica para la construcción de un objeto clase (class) en Python, porque todavía no toca, sino antes bien, en cómo Pickle es capaz de enfrentarse al reto y resolverlo como todo un campeón de la binarización.
Para verlo nos apoyaremos en un ejemplo aportado por Juan Díaz en su magnífico canal de Youtube píldorasinformáticas, cuya visualización, en lo que atañe al curso de Python, que es lo que nos toca y, para quien esté interesado en cualquier otro distinto dentro del ámbito de la informática y la web, recomendamos vivamente.
Vamos allá.

Pidiendo disculpas por usar una terminología que aún no comprendemos, lo que hemos hecho hasta ahora es, a parte de importar la librería pickle, que esto sí, modelizar una clase a la que llamamos vehiculo y, a continuación, definir en el constructor __init__() una serie de propiedades que va a tener en común todo objeto que creemos (instanciemos) dentro de la clase vehiculo. A continuación, definimos tres métodos: mover, estacionar y estado_actual, con su correspondientes bloques de código: en los dos primeros casos una variable a la que asignamos como valor un booleano, y en el tercero, una impresión más elaborada, en la que combinamos cadenas de caracteres literales (string) con llamadas a propiedades y métodos previamente instanciados dentro de la clase vehiculo.
Todo esto lo archivaremos como un fichero con el nombre de módulo toy.py.
No entraremos en más detalles.
A partir de aquí vamos a crear (instanciar) cuatro objetos que asignaremos a sendas variables veh1, veh2, veh3 y veh4 respectivamente, y una variable más, vehs, de tipo lista, para almacenar las cuatro anteriores.

Aquí ya tenemos nuestros cuatro objetos veh1, veh2, veh3 y veh4 primorosamente creados (instanciados) con el paso de parámetros que nos demanda el constructor __init__(), si nos fijamos en el código de la clase vehiculo: una marca y un modelo, que hemos pasado como cadenas. Abajo, la lista vehs con los cuatro objetos instanciados.
A partir de aquí procederemos tal y como lo hemos hecho hasta ahora. Declararemos una variable a la que pondremos por nombre fileb y que almacenará el resultado de la ejecución de la función integrada open() posicionando como primer argumento un nombre de fichero, "vehiculos_varios", (en esta ocasión, obviaremos la ruta para que cree el fichero en el directorio actual, esto es, en el que estemos trabajando) sin necesidad, como también ya sabemos, de introducir extensión alguna; y el modo (mode) "wb" para que cree el fichero propiamente dicho y se pueda escribir sobre él.
A renglón seguido, la obligada llamada a pickle y, a través de la sintaxis del punto, al método dump() que suscitará el volcado de datos en fileb en modo binario, en este caso con los argumentos vehs, que es el objeto Python de tipo lista que queremos binarizar, y el fichero que acabamos de crear con el método open(), donde queremos que se guarde, fileb. Cerramos el fichero con el método close() y, opcionalmente, podemos eliminarlo con la declaración del.

A partir de aquí procederemos tal y como lo hemos hecho hasta ahora. Declararemos una variable a la que pondremos por nombre fileb y que almacenará el resultado de la ejecución de la función integrada open() posicionando como primer argumento un nombre de fichero, "vehiculos_varios", (en esta ocasión, obviaremos la ruta para que cree el fichero en el directorio actual, esto es, en el que estemos trabajando) sin necesidad, como también ya sabemos, de introducir extensión alguna; y el modo (mode) "wb" para que cree el fichero propiamente dicho y se pueda escribir sobre él.
A renglón seguido, la obligada llamada a pickle y, a través de la sintaxis del punto, al método dump() que suscitará el volcado de datos en fileb en modo binario, en este caso con los argumentos vehs, que es el objeto Python de tipo lista que queremos binarizar, y el fichero que acabamos de crear con el método open(), donde queremos que se guarde, fileb. Cerramos el fichero con el método close() y, opcionalmente, podemos eliminarlo con la declaración del.

En el escritorio, señalado con una flecha, vemos refulgente como un Sol de verano nuestro fichero binario vehiculos_varios. Un nuevo éxito para pickle. Veamos ahora qué pasa cuando lo abrimos en el bloc de notas:


Sin comentarios.
Para reconvertir un texto binario en otro legible para el usuario, y como ya hemos aprendido antes, debemos recurrir de nuevo a la función integrada open() asignada a una variable, filenew, donde, de nuevo, pasaremos como primer argumento el nombre del fichero binario, vehiculos_varios, y el modo (mode) en que queremos que se abra, es decir, de sólo lectura y en binario, "rb".
A continuación declararemos una variable, vs, donde almacenaremos la información "traducida" de ese fichero mediante el método load() con el nombre del fichero como argumento. Con la información ya trasvasada a vs, podremos cerrar tranquilamente el fichero filenew con el método close(). Podemos hacer uso del bucle for/in para facilitar la lectura.

Para reconvertir un texto binario en otro legible para el usuario, y como ya hemos aprendido antes, debemos recurrir de nuevo a la función integrada open() asignada a una variable, filenew, donde, de nuevo, pasaremos como primer argumento el nombre del fichero binario, vehiculos_varios, y el modo (mode) en que queremos que se abra, es decir, de sólo lectura y en binario, "rb".
A continuación declararemos una variable, vs, donde almacenaremos la información "traducida" de ese fichero mediante el método load() con el nombre del fichero como argumento. Con la información ya trasvasada a vs, podremos cerrar tranquilamente el fichero filenew con el método close(). Podemos hacer uso del bucle for/in para facilitar la lectura.

Es preciso puntualizar que este ejemplo lo hemos realizado desde el mismo fichero toy.py para poder ver su funcionamiento. Así el intérprete de Python puede reconocer qué es cada item de la lista vs y qué es el método estado_actual() que aplicamos sobre ellos: item.estado_actual(). De no ser así, se lanzaría una excepción de Python.
 |
| VERODES A PUNTO DE FLORECER BAÑADOS EN EL ROCÍO DE LA MAÑANA EN EL BOSQUE VERDE DE TENERIFE. |
SHELVE:
Cuando queremos guardar alguna cosa en casa, normalmente, cosas pequeñas, no demasiado grandes, y tenerla bastante a mano, digámoslo así, por aquéllo de "lo he estado usando, lo dejo un ratito, y ya volveré a usarlo más tarde", como un libro que estamos leyendo poco a poco, una cestita con caramelos o un frasco de colonia o una loción para el afeitado, solemos colocarlos en un estante. Ahí lo ponemos, lo "guardamos", casi a la vista como quien dice y, cuando fuera necesario, con sólo alargar el brazo ya podemos volver a usarlo como si tal cosa.
Para esto sirven los estantes. Y para ésto sirve shelve, que se traduce como eso: "estante". en este "estante virtual" que nos procura amablemente la librería estándar de Python podremos almacenar datos, «pequeños», no demasiado grandes, para recuperarlos luego cuando nos haga falta.
En consecuencia, shelve nos permite también la persistencia de datos: obtenemos el/los dato/s, los guardamos en el estante, cerramos el programa, nos vamos unas tres semanas de vacaciones a Groenlandia, regresamos, encendemos el equipo, abrimos el programa, llamamos a shelve, recuperamos el/los dato/s que necesitamos, y continuamos trabajando.

Para esto sirven los estantes. Y para ésto sirve shelve, que se traduce como eso: "estante". en este "estante virtual" que nos procura amablemente la librería estándar de Python podremos almacenar datos, «pequeños», no demasiado grandes, para recuperarlos luego cuando nos haga falta.
En consecuencia, shelve nos permite también la persistencia de datos: obtenemos el/los dato/s, los guardamos en el estante, cerramos el programa, nos vamos unas tres semanas de vacaciones a Groenlandia, regresamos, encendemos el equipo, abrimos el programa, llamamos a shelve, recuperamos el/los dato/s que necesitamos, y continuamos trabajando.

UNA PINCELADA TÉCNICA:
Con lo que acabamos de decir, podemos colegir que shelve se comporta como una suerte de Base de Datos. En efecto, así es. Pero veamos un poco por encima qué tipo de Base de Datos es.
A) DBM: DataBase Manager → Administrador de Base de Datos.
Nos permite almacenar una cantidad indeterminada de elementos en modo mapa o diccionario, es decir, en pares clave/valor (key/value) que, como reza en el título de esta entrada, se binarizan (se convierten en objetos de tipo bytes, y de aquí el vínculo con pickle, para traer shelve, eso sí, como ya apuntábamos en la introducción, con ciertas restricciones necesarias de tamaño) y que, en lugar de almacenarse en memoria, se almacenan en el disco duro de nuestro equipo y que, subsidiariamente, empata de maravilla con el tipo de dato diccionario de Python.
B) RDBMS: Relational DataBase Management System → Sistema de Administración de Bases de Datos relacionales.
Es el modelo de Base de Datos que todos tenemos en mente. Se basa en el uso de TABLAS, que podemos describir como cuadrículas (grid) que se asemejan a Hojas de Cálculo, y que contienen filas (rows) y columnas (columns) o campos (fields) donde se almacenan los registros. Tanto las TABLAS como la cuadrícula y los registros que contienen se manejan a través de un lenguaje dedicado: SQL, de Structured Query Language, es decir, Lenguaje Estructurado de Consultas, basado en sentencias e instrucciones sencillas, con una amplia modalidad de lenguajes derivados: MySQL, SQL Server, PostgreSQL, NoSQUL, etc.
El módulo shelve se encuadra en el tipo DBM que es la opción adecuada para el uso de pares claves/valor en modo diccionario, como ya hemos mencionado, donde las claves (keys) se construyen como cadenas (string) y como valor, cualquier objeto con el que se pueda hacer pickling (susceptible de convertirse en bytes). Vamos a mostrar un pequeño esquema sobre la base de su funcionamiento:

Concluimos nuestro 'panegírico' de las obras y virtudes de shelve afirmando que estamos ante un módulo solvente y capaz para lograr la persistencia de datos, de manera que el objeto a guardar (dato) recibe un proceso automático de pickling por el que se transforma en bytes, almacenándose en disco y asignado como tal a una clave que pasamos como cadena (string), indefectiblemente, para poder recuperarlo posteriormente, bajo el modelo de diccionario típico de Python.


Vamos a ver en acción el esquema superior con un ejemplo:

1. Importamos el módulo shelve con una importación absoluta.
2. shelve.open("data") abre (o crea si no existe) un archivo que lleva por defecto la extensión .db (su sufijo, suffix) de un archivo shelve, de base de datos llamado data, y que asignamos a la variable db. El archivo shelve de tipo diccionario se llama, pues, data.db.
3. Declaramos una nueva que llamamos escritora, y le asignamos el valor Gabriela Mistral.
4. La parte "interesante": ahora asignamos la variable escritora (que contiene Gabriela Mistral a la clave database_escritores, dentro del estante db = shelve.open("data").
5. Cerramos (siempre debemos hacerlo) nuestro acceso al estante db.
En este punto, el nombre de la variable, escritora, esto es, Gabriela Mistral, se ha almacenado en un estante, shelve, que en realidad es un fichero de datos, data.db, como una particular base de datos. De forma predeterminada, este archivo se encuentra en el mismo directorio desde el que se ejecuta el script.

Realmente, el archivo data.db aglutina tres archivos distintos: data.bak, que es un archivo con extensión .bak de backup, que actúa como respaldo o copia de seguridad; data.dat, que es el archivo que guarda la información; y data.dir, que aunque parezca mentira, es un archivo de vídeo, y que responde a la posibilidad de que lo que se haya almacenado sea un dato multimedia.

Vamos a ver otro ejemplo más. Supongamos que queremos mantener una pequeña base de datos de stocks de ventas de motocicletas. Así podemos elaborar el código que se muestra:

Podemos comprobar que la base de datos se ha creado echando un vistazo a nuestro directorio de trabajo en python (recordemos: en el IDLE de Python, file>open. En la esquina inferior derecha, con la opción predeterminada Python files, hacer clic sobre la flechita🔽para que se abra el desplegable, y seleccionar All files, para que se muestren todos los archivos:

En este ejemplo hemos creado un estante (archivo shelve) con la extensión preceptiva .db en el momento de nombrarlo (por defecto, volvemos a recordarlo, aunque no pasemos la extensión (suffix) Python se la agregará automáticamente): stkmots.db.
Y en este archivo se han almacenado tres objetos shelve, con sus claves (keys) correspondientes pasadas como strings entre corchetes, como marca la sintaxis:

Con el código así, ya tenemos una base de datos de tipo DBM abierta que almacenará los datos en modo binario, tal y como almacena el módulo pickle que ya vimos al comienzo de este capítulo la información: stkmots.db.
Podemos, además, abrir (o crear si no existen) múltiples bases de datos a la vez, escribir a voluntad, y cerrarlas en última instancia con el método close(), cosa que debemos hacer siempre que estemos manejando bases de datos, por seguridad y por gestión de memoria.
Lo comprobamos añadiendo a nuestro código anterior una base de datos nueva para almacenar distintos modelos de cada una de las marcas de motocicletas, advirtiendo que cualquier modificación tanto en el nombre que le demos a archivo shelve como a su extensión, construirá una base de datos diferente:

Y lo comprobamos en nuestro directorio:


De este modo obtenemos un segundo archivo shelve, un segundo estante dentro de nuestra base de datos.

Vamos a verlo aplicado a nuestro primer ejemplo:

En este caso, la recuperación y lectura de la información se realiza en la línea 1. de nuestro código, donde tomamos el objeto almacenado en la clave (key) "database_escritores" dentro del estante data.db, y se lo asignamos a la variable escritora. Llamamos a print() para imprimir en pantalla el resultado, en un proceso análogo a la extracción de un valor desde un diccionario cualquiera:

Vayamos ahora a ejecutar lo propio con nuestro segundo ejemplo:

Vamos a ver ahora un ejemplo de almacenamiento con diccionario:

Observemos que la cláusula finally se ejecutará SIEMPRE en un manejador de excepciones, por lo que nos viene ideal para incluir en ella el método close() de cierre.
Podemos manipular el diccionario con sus métodos habituales. Veámoslo:

Pero los cambios no se almacenarán en el estante al cerrar sesión y volver a llamar a shelve. ¡Ay!

Veamos una solución:

Y una vez abierta una sesión nueva comprobamos que la modificación se ha almacenado en shelve:
La base shelve puede encontrar dificultades para integrarse en procesos multihilo atendiendo a varias aplicaciones a la vez. Sin embargo, para sólo lectura podemos hacer que shelve se abra sólo para este proceso mediante la propiedad flag:

Finalmente, la adición de datos es posible operando con las propiedad writeback que ya conocemos del modo siguiente:

Y ahora podremos hacer cosas como ésta:

Finalizamos con un ejemplo elaborado de uso de shelve:

Haciendo las llamadas correspondientes a las funciones obtendríamos:

CREACIÓN DE UN ARCHIVO shelve:
Básicamente, lo primero que tenemos que hacer a parte, claro está, de importar el módulo en modo absoluto, es la declaración de una variable a la que asignaremos el método open() de shelve, que llevará como único parámetro el nombre de un fichero. No hará falta pasarle sufijo o extensión alguno pues lo generará Python por defecto él solito. Tampoco es necesario decir que un método open() como todos los métodos open() del mundo entero abren (habilitan) cosas: así, el método open() lo que hará es habilitar un espacio, abrirlo, acondicionarlo, donde podamos colocar nuestro estante, como habilitar un rinconcito en la pared de la cocina, entre el fregadero y la nevera, donde montar un estante donde colocar los útiles de limpieza, vamos. Declaramos una segunda variable para almacenar el dato a almacenar en shelve, construimos el diccionario y, finalmente, cerramos la Base de Datos (shelve) con el método close() que, como todos los métodos close() del mundo entero cierran (deshabilitan) cosas.


¡DEJADME! ¡DEJADME, QUE LO EXPLICO YO! EN 1 DECLARAMOS LA VARIABLE, database, QUE ALMACENA EL RESULTADO DEL MÉTODO open() DE shelve. ASÍ SE ABRE (O SE CREA SI NO EXISTE) UN ARCHIVO shelve QUE DEBEMOS PASAR COMO string. CON ESTO CREAMOS EL "ESTANTE". EN 2 DECLARAMOS OTRA VARIABLE, object, PARA GUARDAR EL VALOR QUE QUEREMOS COLOCAR EN NUESTRO "ESTANTE". Y EN 3, INSERTAMOS EL MODO DE ASIGNACIÓN DE VALORES A UNA CLAVE EN PYTHON: EL ELEMENTO database, QUE ES UN DICCIONARIO, RECIBE UN PAR CLAVE/VALOR, DONDE LA CLAVE SE PASA ENTRE CORCHETES COMO string, Y A ESTA CLAVE SE LE ASIGNA COMO VALOR (VALUE) MEDIANTE EL OPERADOR = DE ASIGNACIÓN EL VALOR DE LA VARIABLE object.
Vamos a ver en acción el esquema superior con un ejemplo:

1. Importamos el módulo shelve con una importación absoluta.
2. shelve.open("data") abre (o crea si no existe) un archivo que lleva por defecto la extensión .db (su sufijo, suffix) de un archivo shelve, de base de datos llamado data, y que asignamos a la variable db. El archivo shelve de tipo diccionario se llama, pues, data.db.
3. Declaramos una nueva que llamamos escritora, y le asignamos el valor Gabriela Mistral.
4. La parte "interesante": ahora asignamos la variable escritora (que contiene Gabriela Mistral a la clave database_escritores, dentro del estante db = shelve.open("data").
5. Cerramos (siempre debemos hacerlo) nuestro acceso al estante db.
 |
| AMANECE EN INVIERNO SOBRE EL PICO TEIDE, EN LAS CAÑADAS DEL TEIDE, EN EL CORAZÓN DE TENERIFE. |
En este punto, el nombre de la variable, escritora, esto es, Gabriela Mistral, se ha almacenado en un estante, shelve, que en realidad es un fichero de datos, data.db, como una particular base de datos. De forma predeterminada, este archivo se encuentra en el mismo directorio desde el que se ejecuta el script.

Realmente, el archivo data.db aglutina tres archivos distintos: data.bak, que es un archivo con extensión .bak de backup, que actúa como respaldo o copia de seguridad; data.dat, que es el archivo que guarda la información; y data.dir, que aunque parezca mentira, es un archivo de vídeo, y que responde a la posibilidad de que lo que se haya almacenado sea un dato multimedia.

Vamos a ver otro ejemplo más. Supongamos que queremos mantener una pequeña base de datos de stocks de ventas de motocicletas. Así podemos elaborar el código que se muestra:

Podemos comprobar que la base de datos se ha creado echando un vistazo a nuestro directorio de trabajo en python (recordemos: en el IDLE de Python, file>open. En la esquina inferior derecha, con la opción predeterminada Python files, hacer clic sobre la flechita🔽para que se abra el desplegable, y seleccionar All files, para que se muestren todos los archivos:

En este ejemplo hemos creado un estante (archivo shelve) con la extensión preceptiva .db en el momento de nombrarlo (por defecto, volvemos a recordarlo, aunque no pasemos la extensión (suffix) Python se la agregará automáticamente): stkmots.db.
Y en este archivo se han almacenado tres objetos shelve, con sus claves (keys) correspondientes pasadas como strings entre corchetes, como marca la sintaxis:

Con el código así, ya tenemos una base de datos de tipo DBM abierta que almacenará los datos en modo binario, tal y como almacena el módulo pickle que ya vimos al comienzo de este capítulo la información: stkmots.db.
Podemos, además, abrir (o crear si no existen) múltiples bases de datos a la vez, escribir a voluntad, y cerrarlas en última instancia con el método close(), cosa que debemos hacer siempre que estemos manejando bases de datos, por seguridad y por gestión de memoria.
Lo comprobamos añadiendo a nuestro código anterior una base de datos nueva para almacenar distintos modelos de cada una de las marcas de motocicletas, advirtiendo que cualquier modificación tanto en el nombre que le demos a archivo shelve como a su extensión, construirá una base de datos diferente:

Y lo comprobamos en nuestro directorio:


De este modo obtenemos un segundo archivo shelve, un segundo estante dentro de nuestra base de datos.
 |
| EL MAR DE NUBES, IMPELIDO DESDE EL NORESTE POR EFECTO DE LA CORRIENTE FRÍA DE LAS CANARIAS EN CONJUNCIÓN CON LOS VIENTOS ALISIOS, ENVUELVE CON LA CAÍDA DE LA TARDE LOS PEQUEÑOS CASERÍOS REMONTADOS SOBRE LAS LADERAS DEL SUR DEL MACIZO DE ANAGA, NORESTE DE TENERIFE. |
UNSHELVING (restaurar datos):
Por supuesto, y desde la perspectiva de la persistencia de información, que es la idea básica que subyace a toda base de datos digna de ese nombre, tras escribir los datos y almacenarlos en un ESTANTE (shelve) nos gustaría recuperarlos y volver a disponer de ellos. Podemos conseguir la restauración de información reabriendo el archivo de nuevo con el consabido método open() del módulo shelve, que permite la apertura del archivo .db tanto en modo escritura, como ya hemos visto, como en el de lectura, que vamos a ver ahora. El modo se ve a continuación:


En este caso, la recuperación y lectura de la información se realiza en la línea 1. de nuestro código, donde tomamos el objeto almacenado en la clave (key) "database_escritores" dentro del estante data.db, y se lo asignamos a la variable escritora. Llamamos a print() para imprimir en pantalla el resultado, en un proceso análogo a la extracción de un valor desde un diccionario cualquiera:

Vayamos ahora a ejecutar lo propio con nuestro segundo ejemplo:

Recordemos una vez más que debemos cerrar SIEMPRE una base de datos abierta, sea del tipo DBM, como es el caso de shelve, como RDBMS una vez concluido su trabajo para que no continúe consumiendo recursos de memoria mediante el método close().
USO AVANZADO DE shelve:
Hasta ahora hemos mostrado unos pocos ejemplos de uso de shelve relativamente sencillos. Los objetos shelve, esto es, aquéllos que respondan a la sintaxis *.db, muestran su mayor capacidad y potencia cuando trabajan con colecciones modificables de datos (secuencias). Estamos hablando principalmente de diccionarios y listas.
Aún así, existe una limitación importante: cualquier dato (value) asignado a una clave (key) que leamos desde un objeto shelve (estamos hablando de nombre = dicty['escritora'] o modelo = stock_motocicletas['Yamaha'] para ilustrar el caso a partir de los ejemplos anteriores) no se actualiza de manera automática en el estante si el script cambia.
Basándonos en el ejemplo que devuelve Gabriela Mistral, si tuviéramos que cambiar la variable nombre para que devolviera Alfonsina Storni, esta actualización (updating) no se retrotraería a nuestro objeto shelve: la actualización (updating) no se realiza automáticamente en ninguna base de datos, sea del tipo que sea, para preservar la integridad de los datos almacenados. A este principio responde el hecho de que la solicitud nombre = dicty['escritora'] siga devolviendo Gabriela Mistral y no Alfonsina Storni.
Para conseguir la sobreescritura que deseamos debemos habilitar la propiedad writeback que en inglés, significa precisamente eso: 'sobreescribir', y a la que asignamos el valor True, dado que su valor predeterminado, obviamente, y de acuerdo con la preservación de los datos almacenados en la base de datos, es False (writeback = True) para que pueda ejecutar sobre la marcha un proceso de updating a nivel interno: db = shelve.open("data", writeback=True).
La introducción de writeback=True puede resultar muy útil y hasta recomendable según los casos. Pero debemos tener en cuenta que cualquier cambio que se realice durante la ejecución se almacena en memoria volátil caché hasta que se cierra (de nuevo la importancia de cerrar la base de datos con el método close()) el archivo-estante shelve. De esta manera, será el último valor asumido por la clave antes de su cierre el que se mostrará finalmente cuando recuperemos la información.
Para acabar, una manera recomendable de administrar un script para importar una colección de datos a un objeto shelve cuando se ejecuta por primera vez, con ítems desconocidos, puede ser creando un gestor de contexto con with (v. with) dentro de un bucle infinito (while True) "mientras todo vaya bien..." y un manejador de excepciones try/except:


 |
| EROSIÓN, LAVA, ATLÁNTICO Y AMANECER EN LA COSTA DE EL PALMAR, ARONA, CON EL PERFIL DE LA MONTAÑA DE GUAZA A LA DERECHA DE LA IMAGEN. PAISAJE COSTERO TÍPICO DE LA COSTA SUR DE TENERIFE. |

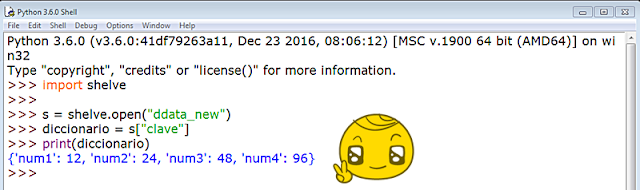
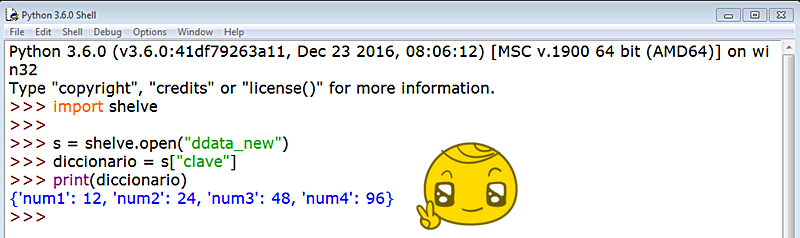
Observemos que la cláusula finally se ejecutará SIEMPRE en un manejador de excepciones, por lo que nos viene ideal para incluir en ella el método close() de cierre.
Podemos manipular el diccionario con sus métodos habituales. Veámoslo:

Pero los cambios no se almacenarán en el estante al cerrar sesión y volver a llamar a shelve. ¡Ay!

Veamos una solución:

Y una vez abierta una sesión nueva comprobamos que la modificación se ha almacenado en shelve:
La base shelve puede encontrar dificultades para integrarse en procesos multihilo atendiendo a varias aplicaciones a la vez. Sin embargo, para sólo lectura podemos hacer que shelve se abra sólo para este proceso mediante la propiedad flag:

Finalmente, la adición de datos es posible operando con las propiedad writeback que ya conocemos del modo siguiente:

Y ahora podremos hacer cosas como ésta:

Finalizamos con un ejemplo elaborado de uso de shelve:

Haciendo las llamadas correspondientes a las funciones obtendríamos:

 |
| VOLCÁN DEL CHINYERO, ENTRE LOS MUNICIPIOS DE SANTIAGO DEL TEIDE, GARACHICO Y EL TANQUE, CAUSANTE DEL ÚLTIMO EPISODIO ERUPTIVO HISTÓRICO EN LA ISLA DE TENERIFE, HACIA 1909. |




