 |
| ROQUES DE DENTRO (EL MAYOR) Y FUERA (EL QUE ASOMA A LA IZQUIERDA), FRENTE AL CASERÍO DE LAS PALMAS DE ANAGA, ABAJO, PARTE NOROCCIDENTAL DEL MACIZO DE ANAGA, NORESTE DE TENERIFE. |
Vamos a comenzar fuerte y nos disponemos a mostrar varias tablas con los métodos de la biblioteca re de Python que traducen a este lenguaje de programación todas las virtudes del recurso a las expresiones regulares, regex, que hemos visto hasta ahora. Así que... ¡a la manteca!
TABLAS DE MÉTODOS DEL MÓDULO re:

TABLAS DE MÉTODOS DEL OBJETO re:

ATRIBUTOS Y MÉTODOS DE OBJETOS CONCORDANTES (MATCHER):
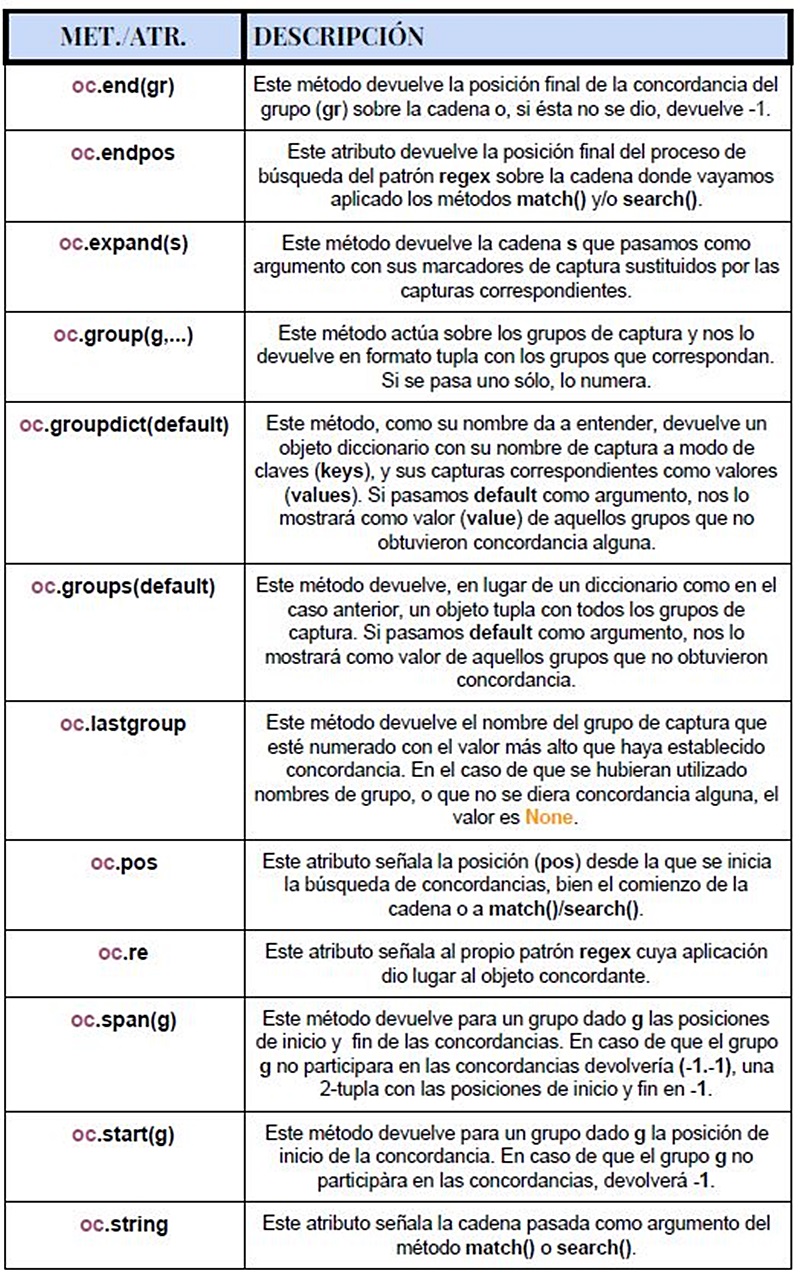
Veamos a continuación cómo trabajar con los métodos y atributos más utilizados en el contexto de las expresiones regulares.
 |
| CASCADA DE SAL, EN LA COMARCA DE LA TIERRA DEL TRIGO, NOROESTE DE TENERIFE. |
BÚSQUEDAS
Constituye el campo de actuación por antonomasia en las regex y el método search() es, por su parte, su recurso fundamental. Recordemos aquí su sintaxis: re.search(regex, cadena, [marcador]), donde regex es el patrón que pasamos como primer argumento (el principal) y cadena, que pasamos como segundo, el ámbito de aplicación del patrón, pudiendo pasar como argumento opcional un marcador para perfilar y definir aún más la devolución del método.
Básicamente, funciona buscando una subcadena (el patrón regex) dentro de la cadena proporcionada. Veamos un ejemplo sencillo:

Tras la importación pertinente de la librería re, llamamos en 1. al método search(). Insertamos primero el carácter r que le viene a decir al intérprete de Python: "Oye, fíjate bien, que esto que viene a continuación es un patrón regex". Sin embargo, como comprobamos más abajo, en las versiones más recientes del programa podemos prescindir del carácter r obteniendo los resultados esperados sin ningún problema.
En 2. tenemos una línea de comprobación donde se nos dice que se ha obtenido un objeto match (matcher) como resultado de la búsqueda. span=(4,7) es una tupla que nos indica los índices de inicio y final de la rebanada (slice) de la cadena donde se ha encontrado la concordancia (recordemos que los índices empiezan a contar de izquierda a derecha desde 0 y que el índice final siempre es un número superior al real y que no se tiene en cuenta: span=(4,7) = "cocodrilo"[4:7]). A continuación se nos muestra el objeto match: match='dri'.
Si queremos ver el resultado impreso en pantalla debemos asignar una variable al patrón regex, como hacemos en 3. y luego, a continuación, en 4., asignarle a su vez el método group().
Para ver el resultado, como acabamos de decir, y que nuestra búsqueda de coincidencias adquiera funcionalidad y consistencia en nuestro código, debemos declarar una variable a la que asignar el método search() de búsqueda. Así, podremos aplicar los distintas atributos y los métodos propios al resultado obtenido, siendo el más importante de todos éstos el método oc.group(g,..) que hemos conocido en la tabla de ATRIBUTOS Y MÉTODOS DE OBJETOS CONCORDANTES y que nos devuelve la subcadena resultante de la ejecución del método search().
Como vemos, nos devuelve el patrón regex, 'dri', que le pasamos como argumento lo que, en sí mismo, no parece tener mucho sentido. ¿Entonces? ¿Qué utilidad tiene? Tranquilidad, calma y sosiego: su funcionalidad sólo podemos extraerla haciendo uso de los caracteres regex. Veámoslo:

Fijémonos que en el ejemplo anterior la primera búsqueda falla porque a la cadena "dri" le hemos antepuesto el símbolo ^, que indica que con ella debe iniciarse el texto. Y "cocodrilo" no empieza por "dri" como sí ocurre con el texto "dribbling" que pasamos en la búsqueda siguiente.
Veamos algunos sencillos ejemplos más:
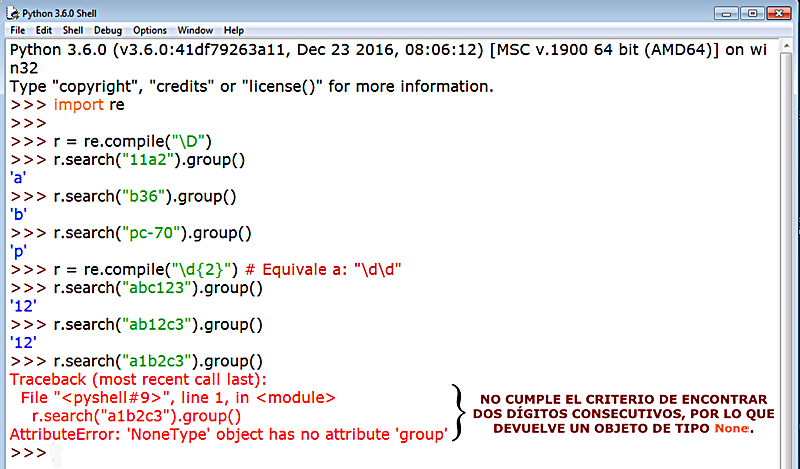
El método group() del objeto concordante (el matcher, que así se llama) nos permite usar paréntesis a la hora de construir nuestro patrón regex, y agrupar así las subcadenas concordantes, abriéndonos a nuevas posibilidades en nuestras búsquedas. Veamos un ejemplo: queremos crear un patrón que por un lado devuelva dos números consecutivos y una secuencia de letras minúsculas lo haríamos así:
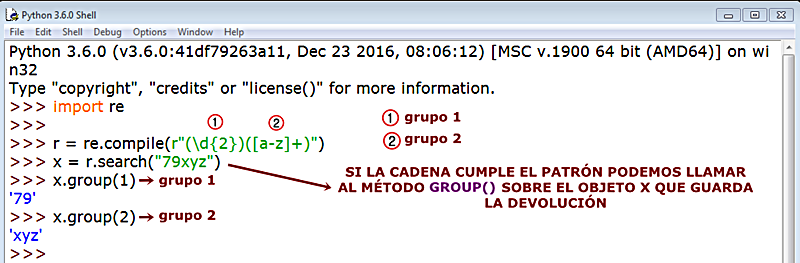
Si usamos el índice 0 como argumento de group() nos devuelve la cadena entera:
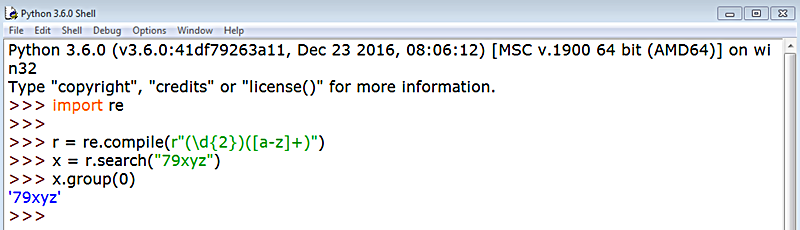
Podemos también llamar al iterador groups() sobre el matcher, el objeto x, y que nos devolverá un iterable en forma de tupla con los resultados de cada grupo (1 y 2), pero sin el grupo 0 que, como acabamos de ver nos devuelve la cadena entera.

Veamos una aplicación del método groupdict() para generar un objeto de tipo diccionario a partir de los nombres de grupo y los resultados posibles:

Los objetos devueltos por la aplicación de los métodos search() y match(), que veremos ahora, son objetos de tipo matcher, con lo que la variable x, en el ejemplo anterior almacena un objeto matcher resultante de la aplicación del método search() de las regex sobre una expresión concreta: "79xyz". Los métodos group() y groups() que hemos llamado lo son del objeto matcher pero no del objeto regex r.
Al contrario que search(), el método match() devuelve None si no establece una concordancia al principio de la cadena, mientras que search() la busca a lo largo de la misma.

Para el último caso Python lanza una excepción porque el patrón regex no se encuentra al comienzo de la expresión, por lo que se genera un objeto None.
Podemos continuar aplicando atributos y métodos del objeto matcher como son re y pos:

 |
| COBERTURA FORESTAL DE TILOS EN EL BOSQUE DEL AGUA, PRÓXIMO AL MUNICIPIO DE LOS SILOS, NOROESTE DE TENERIFE. |
La propiedad string, simplemente, nos devuelve la cadena de búsqueda mientras que endpos nos devuelve el índice del carácter literal donde termina la búsqueda, de tal modo que pos y endpos engloban la zona de búsqueda de concordancias sobre el texto de un determinado patrón regex:

Vemos a continuación algunos métodos de grupo:

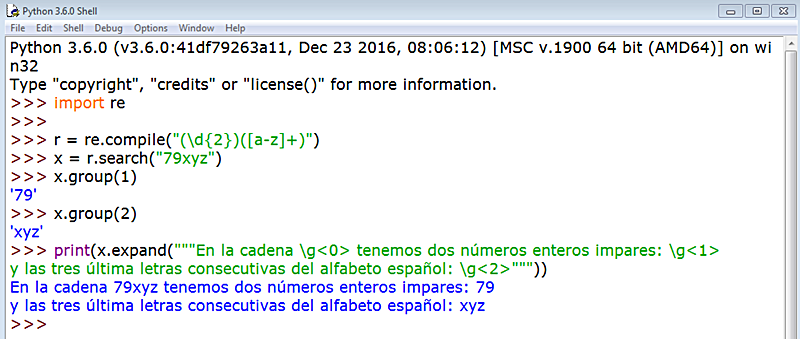
Prosiguiendo con los procedimientos que podemos aplicar sobre un objeto matcher, uno de los más interesantes y expansivos es el 'referenciador' \g ('referenciador' porque hace referencia a algo. ¿A qué? Al grupo, cuando disponemos de ellos, y de aquí la g minúscula: grupo). El 'referenciador' se utiliza con el método expand(string) y nos permite insertar en ella los grupos obtenidos de acuerdo con su número devolviendo una cadena nueva con los grupos inscritos señalados por el 'referenciador'. La contrabarra es, obviamente, el escape que permite a Python identificar a g como lo que queremos que sea, un 'referenciador' sustrayéndolo de la literalidad del texto. Finalmente, colocamos entre ángulos el número del grupo: <número_de_grupo>. Veámoslo:
Contamos con otras dos funciones más de búsqueda: si presumimos que a la hora de aplicar un patrón regex a una expresión vamos a encontrar más de una coincidencia, nos vendría bien utilizar el método findall(), "encontrarlo todo", que recorre de cabo a cabo la expresión a la caza y captura de concordancias. Nos devolverá así, empleada junto a los grupos, una tupla donde muestra todas las concordancias. También es posible recurrir a ella directamente sin emplear grupos, lo que nos devuelve una lista simple con las coincidencias ordenadas por orden de concurrencia. El optar entre una y otra dependerá de nuestras necesidades de codificación.
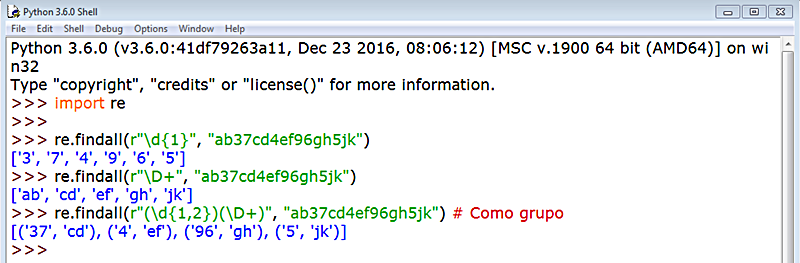
Paralelo al método re.findall() tenemos el método re.finditer() que, como su nombre sugiere, devuelve un objeto iterador que podemos usar para localizar concordancias en un texto. Vemos un ejemplo de uso: veamos un ejemplo de regex para localizar palabras duplicadas:

Declaramos una variable donde almacenaremos nuestro flamante patrón regex, x en nuestro ejemplo, y que compilamos (recordemos que, aunque lo hemos puesto, el referente r no es necesario) para su reutilización, como ejercicio de buena práctica en codificación.
Con el afirmador ?P sobre <palabra> (grupo nombrado o nominado por el que será invocado, y no por su índice, lo que, al igual que sucede con los diccionarios frente a las listas nos procura un mayor y mejor control sobre las llamadas) nos aseguramos que encontrará las máximas concurrencias posibles sobre el texto que pasemos. El uso de grupos nominados resulta muy útil con patrones regex complejos, evitándonos incongruencias: si por ejemplo modificáramos la estructura del regex para agregar nuevos grupos Recordemos que los nombres de grupo se implementan con los caracteres ?P entre el paréntesis de apertura que engloba al grupo mismo y un nombre cualquiera, el que queramos, inscrito entre ángulos → (?P<nombre>patrón_regex). Esta estructura nos permite, además, construir diccionarios mediante el método group.dict(), con pares nombre_de_grupo:contenidos.

Con el marcador re.IGNORECASE, aunque aquí no tiene mucho sentido dado el patrón que pasamos, que busca dígitos y no caracteres literales, pues no se pierde tampoco nada y, con sólo sustituir \d+ por \D+, ya nos valdría primorosamente.
A continuación introducimos la iteración en nuestro código. El bucle for/in circulará por cada objeto concordante devuelto por el método re.finditer(string), y el método matcher.group(nombre) para recuperar el texto de grupo devuelto.
Habremos observado que en el ejemplo anterior hemos introducido en el patrón regex lo que se denomina un LIMITADOR DE PALABRA, esto es, \b (v. tabla de afirmaciones), lo que nos permite tener la certeza de que la búsqueda de concordancias empieza a llevarse a cabo desde el comienzo mismo del texto mismo cuyas duplicidades queremos encontrar. Pero es que, además, incorpora mayor claridad a la devolución: si no recurrimos a ella, como en el ejemplo de re.finditer(string), se nos devolverá el resultado repetido tantas veces como duplicidades haya detectado: dos en el ejemplo. Con \b, tan sólo nos informa que se ha encontrado duplicidades, sean dos, cien o un millón sobre el texto, sin repetirlo dos, cien o un millón de veces.

 |
| ROQUE DE TABORNO, MACIZO DE ANAGA. NORESTE DE TENERIFE. |
SUSTITUCIONES
Las sustituciones o reemplazos de texto sobre otro texto lo que, por cierto, debería traernos a la memoria el método str.replace() de las strings puesto que su funcionalidad será muy similar, se ejecuta por mediación del método regex sub(), una suerte de combinación sincrética entre los métodos search() y expand() que ya hemos estudiado. con el propósito de encontrar primero toda concordancia sobre el texto dado con el patrón regex y sustituirlas por otra cadena distinta que pasaremos como argumento, de manera que en su sintaxis más básica llevará como argumentos obligatorios, igual que sucede con str.replace(), el patrón de sustitución (la cadena de sustitución, vamos) y, a continuación, el texto sobre el que vamos a aplicar el patrón.
Por defecto, lleva a cabo todas las sustituciones posibles cada vez que localiza una coincidencia, aunque con el parámetro opcional n podremos limitar, si lo estimáramos oportuno, el número de sustituciones a realizar.
Veamos su sintaxis más ampliamente:

El método sub() trabaja también con grupos que podremos reemplazar por diferentes cadenas según nuestras necesidades:

SEPARACIONES
Las separaciones se llevan a cabo con el método split() de los patrones regex, y su acción es similar a la del método homónimo de las strings, con la diferencia que en el primer caso podemos introducir regex en su argumentado.
La ejecución del método devuelve igualmente un iterable (recordemos que un iterable es toda secuencia capaz o susceptible de ser recorrida por un bucle for/in de principio a fin y de izquierda a derecha) de tipo lista donde se almacenan los elementos resultantes de la aplicación del "corte", con cada concordancia con el separador, de izquierda a derecha.
Podemos insertar un limitador n para determinar el número de separaciones (elementos) que queramos obtener.

MODIFICADORES
Los marcadores/modificadores hacen precisamente eso: modificar el comportamiento original de los patrones regex, bien extendiendo sus atribuciones o bien limitándolas.
los marcadores/modificadores se asocian a un patrón regex siempre y cuando usemos el método re.compile(), insertándolos como segundo argumento.
Por otra parte es posible "afinar" la captura de concordancias de un patrón sobre un texto sumando varios marcadores/modificadores, separándolos por el marcador de barra vertical: |.


PARA FINALIZAR CON LA MAJADERÍA ESTA DE LAS REGEX OS VOY A PROPONER UN PAR DE ENLACES QUE OS PUEDEN RESULTAR DE PROVECHO: EL PRIMERO ES UN ENLACE A Pythex.org QUE NOS PERMITE COMPROBAR ON LINE Y DE MANERA GRATUITA LA IDONEIDAD DE NUESTRAS REGEX ANTES DE PASARLA A CÓDIGO. EL SEGUNDO ES UN ENLACE A UNA PÁGINA QUE YA CITAMOS EN UNA ENTRADA DEDICADA A LA INSERCIÓN DE SÍMBOLOS UNICODE EN NUESTRO CÓDIGO, Y QUE TAMBIÉN MUESTRA VARIOS EJEMPLOS INTERESANTES DE REGEX YA CONSTRUIDAS LA MAR DE ÚTILES. SI ALGUIEN ME QUIERE RASCAR TRAS LA OREJITA...
- Pythex.org → Probador de patrones regex
- Un poco de todo → Ejemplos de patrones regex (y otras cosas)
 |
| SENDEROS TAMIZADOS DE HOJARASCA ATRAVESANDO MONTES DE LAURISILVA, NOROESTE DE TENERIFE. |
No hay comentarios:
Publicar un comentario