 |
| DISTINTOS ESTRATOS DE LAVA EN UN BARRANCO DE ARICO, SUR DE TENERIFE |
Antes de comenzar, una pequeña puntualización: hemos decidido separar en un capítulo aparte las strings y sus métodos por cuestiones de espacio y cansancio lector. Ambos apartados son muy extensos en cantidad y muy prolijos en datos, muy densos, lo que perjudica nuestra capacidad de comprensión y así como de la asimilación de la información vertida en ellos. Para los siguientes tipos de datos, que también cuentan con sus métodos respectivos, será posible unir ambos temas en un mismo apartado. Hecha la aclaración, pongámonos las pilas.
Entramos aquí con los METHODS, los "MÉTODOS", de las strings. Si hacemos memoria podríamos recordar que al comienzo de este manual proporcionábamos una definición simple pero eficaz de lo que era un método: Las cosas que podemos hacer con un objeto. Ahora, este objeto son las strings. Y, a parte de lo que hemos estudiado ya, ¿qué otras cosas podemos hacer con ellas?
Existen un buen puñado, la verdad. Como tales métodos existen todavía algunos más que no vamos a recoger aquí, porque su uso es muy específico, restringido o muy poco frecuente y no aparecen o no se usan en el 99.9% de las ocasiones. Prescindiremos de ellos.
Un método es una función (hace cosas, produce un resultado, ejecuta una acción concreta) y, en consecuencia, muestra una estructura sintáctica similar, con sus paréntesis reglamentarios al cabo del nombre de la función, lleven o no parámetros.
Por otra parte, y adelantándonos en unos cuantos capítulos al concepto de LIBRERÍA de Python, los métodos parecen que, en el caso de las cadenas que nos ocupan ahora, provinieran de una especie de librería propia, característica, exclusiva, de las strings y que el lenguaje, apoyándose en un criterio de mayor usabilidad y eficiencia para nosotros, programadores, en el momento de codificar, hubiera decidido prescindir de las sintaxis de importación de librerías y proporcionarles una categorización propia (métodos) para facilitar el acceso a los mismos.
Vaya tela, ¿verdad? Imaginemos que trabajamos en una famosa pizzería con más de 20 pizzas a la carta y que somos los cocineros (programadores) expertos en preparar suculentas pizzas (programas). Por una de esas casualidades de la vida resulta que nueve de cada diez clientes (personas que nos piden que les programemos algo) que acuden a nuestro restaurante (estudio de programación, o algo así) nos piden las mismas 5 0 6 clases de pizza, bien porque sean las más baratas, las más sabrosas, las mejor recomendadas o por una mezcla de todos estos motivos. Y, también casualmente, resulta que esas mismas pizzas utilizan más o menos los mismos ingredientes (funciones: la función "queso", la función "tomate", la función "albahaca", la función "anchoa", etc,). Vista la situación, nuestro gestor de empresa (Python) echa cuentas y nos dice:"Vamos a ver: Como parece que todas las pizzas que preparamos son las mismas y con los mismos ingredientes a éstos, en concreto a éstos(la función "queso", la función "tomate", la función "albahaca", la función "anchoa", etc,), en lugar de almacenarlos junto a los demás en el enorme depósito que tenemos cuatro pisos más abajo (librerías) de la cocina, como se utilizan más y se consumen más rápido, conviene tenerlas más a mano. Así que vamos a recoger todos estos ingredientes, los etiquetamos (métodos) y los ponemos más a manos, en la despensa que tenemos justo en la puerta de al lado (funciones integradas de Python de acceso rápido)".
Y así todos contentos.
¿Lo entendemos mejor así?
Como conclusión antes de pasar a estudiar los métodos debemos saber que la Programación Orientada a Objetos, POO por sus siglas en castellano, en la que también se apoya Python y la gran mayoría de los lenguajes de programación modernos. (Sobre la POO hablaremos al comienzo del segundo manual de Python) utiliza los objetos, y recordemos que para Python TODO son objetos, que son entidades que tienen un determinado estado, un comportamiento (método) específico y, cómo no, una identidad particular en sus interacciones, para diseñar aplicaciones y programas informáticos (tomado de la WIKIPEDIA). De la POO Python incorpora para llamar a los métodos una sintaxis que la distingue:
nombre_objeto.nombre_método(parámetros)
La clave del asunto se encuentra en el elemento más ínfimo de la fórmula anterior: el punto que separa a nombre_objeto de nombre_método(parámetros) y que en Python se denomina OPERADOR DE PUNTO u OPERADOR PUNTO. ¿Operador de qué? ¿Sobre qué opera? Pues de ACCESO A ATRIBUTO. ¿Y qué significa esto? Que el punto nos permite tener acceso a los atributos/propiedades y a los métodos de un objeto determinado. A su vez, tengamos en cuenta que un atributo/propiedad y un método son, al mismo tiempo, objetos que, como tales objetos, pueden tener sus propios atributos/propiedades y sus propios métodos. Y estos también los suyos, y así sucesivamente "ad infinitum". A todo esto, desde lo más genérico hasta lo más concreto, hasta el atributo/propiedad y/o método deseados, podemos llegar a través del punto, utilizando todos los OPERADORES DE PUNTO necesarios para conseguir ese atributo/propiedad o método que andamos buscando. A esto es lo que se llama DOT METHOD o DOT NOTATION, esto es, "MÉTODO DE PUNTO" o "NOTACIÓN DE PUNTO".
2) STR.CENTER(ANCHO, CARÁCTER DE RELLENO):
Este método nos permite centrar una string entre un carácter (uno sólo) que elijamos, a la izquierda y a la derecha de nuestra cadena.
Como argumentos lleva, primero, el largo total de la cadena. Llama la atención que, en el cuadro de ayuda en lugar de 'length', cuya contracción, 'len', representa el nombre de la función len() ya conocida por nosotros y que nos devuelve la longitud de una cadena, se sustituya aquí por 'width'. Esto es así porque el 'width' determina el ancho/largo que nosotros le queremos dar a la cadena, y no al ancho/largo que tenga por sí misma y que podemos calcular a través de la función len(). tal y como se verá en los ejemplos. Si el len() de la string fuera igual al 'width' que proponemos no tendría sentido añadir ningún carácter de relleno para centrar la cadena en tanto que no sobra espacio alguno ni a derecha ni a izquierda; y segundo, el carácter que hayamos seleccionado para rellenar a la derecha y a la izquierda de la cadena para centrar nuestra string.
Ambos elementos, como ocurre con todos los diferentes argumentos que se pasan a una función, deben ir separados por comas.
Una buena práctica pasa por calcular previamente la longitud de nuestra string apoyándonos en la función len() que conocemos bien, y determinar cuántos caracteres queremos añadir a ambos lados. Podemos calcular los que queremos tener a la izquierda, lo multiplicamos por dos para incluir los de la derecha y, finalmente, esta cantidad se la sumamos a la devolución de la función. La cifra que obtengamos será la que pasemos como primer argumento del método:
Como hemos visto, por norma general, siempre podemos introducir cualquier método como argumento en una función print().
3) STR. COUNT(SUB, ÍNDICE DE INICIO, ÍNDICE FINAL):
Este método como sugiere su nombre, tiene por cometido "contar". ¿Y qué cuenta? Pues las substrings (sub) iguales que existen entre el índice de inicio (start) y el índice final (end). Por eso, como argumentos lleva la substring que queremos contar, bien sea un único carácter literal o una substring formada por n caracteres literarios (donde n es cualquier número entero), desde dónde debe empezar a contar (índice de inicio) y hasta dónde debe hacerlo (índice final), con los argumentos separados por comas.
éste método es muy útil. por ejemplo, para localizar el número de veces que se repite una palabra o un signo en un texto, cualquiera que sea su longitud.

En el cuadro de ayuda se muestra un listado completo de todos los métodos asociados a las strings. Pero en este capítulo no nos vamos a ocupar de todos ellos. Los que se expongan a continuación son los más habituales, los de uso más frecuente y que conviene conocer mejor. Incluso se introducirá alguno que se complementará a posteiori con una entrada aparte por su importancia y profundidad a la hora de mejorar nuestros códigos. Los que no se incluyan aquí serán aquéllos que tengan un uso mucho más restringido y/o exclusivo. Aún así, dispondrán de sus propia entrada para que, al menos, nos hagamos una idea de ellos.
4) STR.ENDSWITH(SUFIJO, ÍNDICE DE INICIO, ÍNDICE FINAL):
Éste nuevo método, que puede traducirse líbremente como "termina con...", trabaja con booleanos. Devuelve True si nuestra string acaba con el sufijo (suffix) que le hayamos pasado previamente como argumento. Podemos utilizar los índices de inicio y final (start y end) para restringir la búsqueda del intérprete a un pedazo concreto de la string. Su uso es optativo, a menos que queramos acotar explícitamente una secuencia de la string.

No dejemos de consultar la entrada dedicada a los tipos de datos None y Booleano: Nos ayudará a tener las ideas mucho más claras a la hora de entender bien éste y otros métodos de las strings. Es un consejo de amigo perruno, ¿eh?.
Un aspecto a tener en cuenta es el concepto pythoniano de "sufijo" (suffix). Básicamente, Python entiende por ello la terminación de una string, ya sea éste un único carácter literal, una palabra completa en un texto o un conjunto heterogéneo de caracteres literarios o substrings. La única condición que debe cumplir indefectiblemente para que el intérprete de Python lo considere como un sufijo hecho y derecho es que esté al final de la string.
Mostramos un ejemplo para entenderlo mejor.
En este caso, obtenemos True. Como podemos ver, es más sencillo y natural obtener los resultados deseados leyendo de izquierda a derecha que haciéndolo al contrario, más complejo de hacer e, incluso, de entender. Un consejo: siempre que podamos, y esto forma parte de la filosofía del lenguaje (ver la entrada que dedicaremos al ZEN de Python), hagamos las cosas lo más simples posible.
Sumamos estos ejemplos para subrayar un par de aspectos que ya conocemos: en los dos primeros casos hemos añadido un índice de inicio pero no un índice final. Recordemos que si en una slice no introducimos uno de los índices, el intérprete de Python, si colocamos el índice final pero no el de inicio, entenderá que la rebanada empieza desde el principio, str[0]; y al revés, si colocamos el índice de inicio pero no el índice final, entenderá por contra que la rebanada termina con el último carácter que encuentre, aquél justo antes de la comilla de cierre. Por eso, en ambos casos, la aplicación del método nos devuelve True.
En el tercer caso hemos omitido el índice de inicio pero no el índice final. Pero Python no admite, sintácticamente hablando, el dejar un espacio vacío entre comas, el que correspondería al índice de inicio. Con ello, "subrepticiamente" nos obliga a incluir siempre, como mínimo, el índice de inicio en el caso de recurramos a los índices para acotar una substring.
Pero existe, sin embargo, una manera de solventarlo: usando el objeto None, que como sabemos si hemos leído la entrada correspondiente, es un tipo de dato de Python que significa, resumidamente, "ninguna cosa", pasado como índice de inicio. Veámoslo con un ejemplo:
En el último caso, podemos comprobar una vez más la sensibilidad de Python al uso de mayúsculas y minúsculas.
Proponemos una entrada nueva:
T1. LOS OPERADORES 'IN' E 'IS'. PERTENENCIA E IDENTIDAD.
5) STR.EXPANDTABS(TABSIZE=8):
Aquí tenemos un método peculiar. Su función consiste en devolver una copia de nuestra string de tal modo que los espacios de tabulación (separación) van siendo ocupados por caracteres de nuestra string hasta rellenar, si es necesario, todo el espacio de tabulación.
Dicho esto, vamos por partes: para que esto ocurra, debemos decirle a Python que nuestra string está tabulada porque queremos que la separación entre una substring y otra substring diferente sea de n espacios. ¿Y cómo se lo decimos? Pues con otro escape... El escape '\t'.
Vamos a ver qué hace este nuevo escape:
Por otra parte, de acuerdo a la longitud de la substring (la devolución de su 'len()', o si lo preferimos, su número total de caracteres, que es lo mismo), éstas van ocupando los espacios en blanco que indiquemos en el tabsize dejando el resto sin rellenar. Tengamos en cuenta que el separador no se cuenta.
Para ver el resultado de manera correcta debemos acudir a la función print().
Podremos entender mejor las cualidades del método si lo vemos con un ejemplo:
Para este primer ejemplo hemos escogido una string formada por caracteres exclusivamente numéricos. No olvidemos que cualquier número, que es un tipo de dato en sí mismo, cuando se coloca entre comillas pasa a ser una string, con todas sus características y propiedades. Cada uno de estos caracteres lo hemos separado por el preceptivo escape '\t' para poder aplicar el método. Observamos que se guarda por defecto la tabsize igual a 8, y cómo cada uno de las subcadenas separadas entre los escapes (01, 012, 0123, 01234) van progresivamente ocupando los espacios vacíos hasta completar el tamaño total: 8. Por ejemplo, entre 01 y 012 restan 6 espacios en blanco, ya que la suma de estos 6 caracteres más los dos que ocupan 01 tenemos 8, eso sí, contando de izquierda a derecha. Lo podemos comprobar en el ejemplo 1.
En los casos 2. y 3. hemos hecho lo propio modificando el tabsize a nuestro gusto. Notemos cómo las strings van "comiendo" espacios hasta completar el tamaño de la tabulación.
En el ejemplo 4. hemos introducido un entero negativo (obsta decir que ni se nos ocurra introducir un decimal si no queremos que Python nos lance una excepción). Aquí ya no hay tabulación que valga. Aunque Python no nos da error en tanto que hemos pasado un entero, al ser éste negativo, se anula el método y la separación entre los caracteres se reduce a un único espacio en blanco, independientemente del ancho de las subcadenas.
Por último, en el caso 5., hemos querido pasar como argumento una expresión aritmética simple. Comprobamos que la devolución coincide exactamente con la del ejemplo 3. En ambos casos, el tabsize es igual a 12.
Para finalizar, hemos dejado a la vista el cuadro de ayuda del método donde podemos ver que la tabsize que incluye por defecto es igual a 8 espacios en blanco, la misma que '\t'.
Acabamos con la explicación del método aportando un ejemplo más, con frutas, para hacernos más dulce el trago de tanta tabulación. El ejemplo final demuestra de una manera gráfica cómo cuenta el intérprete de Python el tabsize o '\t'.
6) STR.FIND(SUBSTRING, ÍNDICE DE INICIO, ÍNDICE FINAL):
Con este nuevo método podemos encontrar ("to find", "encontrar") el índice que corresponde a una substring, dentro de una string, que pasemos como argumento. Del mismo modo que hemos visto en métodos anteriores, la inclusión de un índice de inicio y/o un índice final es opcional, con el propósito de acotar un espacio estimado donde rastrear. Si solicitamos la búsqueda de una substring que se repite más de una vez, Python nos devuelve el índice del primer lugar donde la encuentre bajo la premisa "primera identificación de la substring => índice". Esto sucederá así a menos que acotemos el espacio de búsqueda de la substring en un espacio distinto.
Cuando la substring esté compuesta por más de un carácter, Python devolverá el índice del primer carácter, pero no los índices de inicio y final de la substring que pasamos como argumento: nos devuelve un int que apunta a un índice específico pero no una slice, con sus índices de inicio y final.
Si el método no encuentra lo que le pedimos devuelve -1.
En el ejemplo que mostramos a continuación empatamos una verificación mediante el recurso al operador de pertenencia, para saber de antemano si tal substring está presente en una string dada, con el método str.find(...) para localizarla, en el caso de que el verificador devuelva True, por el índice de su primer carácter:
7) STR.FORMAT(*ARGS, **KWARGS):
Este método que traemos ahora aquí es bastante más singular en su funcionalidad que lo que hemos visto hasta ahora. Básicamente, el método str.format(*args, **kwargs) ejecuta un "formateo de salida de datos", un "DISPLAY", una forma de presentar el resultado de la ejecución de un script o programa a la vista del usuario. La string que recibe este método incorpora lo que podemos llamar un CAMPO DE REEMPLAZO que queda delimitado de manera gráfica mediante llaves: {...}.
Cada campo de reemplazo o de sustitución puede contener dos tipos de datos: el índice de un argumento posicional (*args), o el nombre de una palabra reservada, keyword, (**kwargs). La ejecución del método devuelve una copia de la string original donde cada campo de reemplazo, ya que pueden coexistir varios de ellos, los que queramos, dentro de una misma string se sustituye por el valor que le corresponda.
¿A que no nos enteramos de nada, eh? Claro, es que dicho así... ¿Qué tal si ponemos un ejemplo para entender mejor de qué va la cosa? Venga.
Observemos que los campos de reemplazo mantienen un orden estricto: primero {0}, luego {1}, a continuación {2}, y así sucesivamente. El orden es tan estricto que si cambiáramos el orden y, por ejemplo, escribiéramos {2} y luego {1}, al intérprete de Python le daría el telele y lanzaría una excepción advirtiéndonos de que estamos "out of range", fuera del orden preestablecido para el método str.format(), que a fin de cuentas, es el mismo orden lógico de los números naturales: 0, 1, 2, 3, 4, 5,..
Podemos comprobar cómo los campos de reemplazo pueden ser números, expresiones (recordemos que una expresión representa a su propia devolución, esto es, 4 + 5, por ejemplo, representa al int 9), strings, etc.
Este método, entre otros procesos, resulta muy útil en operaciones complejas en las que tenemos con trabajar con un número indeterminado de variables desconocidas, por ejemplo, las que almacenes los inputs de usuarios a preguntas del programa, como: "Introduzca un número entre 0 y 10".
Aquí tenemos otro ejemplo más de uso del método que estamos tratando con la inclusión en el segundo campo de reemplazo de una keyword (kwarg), en esta ocasión, una vieja conocida nuestra: la función type().
Para finalizar, un dato importante: los campos de reemplazo deben ser números enteros. Aunque Python reconoce el orden alfabético donde "a" va primero, "b" después, "c" a continuación y así sucesivamente, el método no admite el uso de caracteres alfabéticos en los campos.
Como ya hemos visto, resulta fundamental el orden en que pasemos los argumentos en str.format(), de tal modo que el primer argumento se corresponde con {0}, el segundo argumento con {1}, el tercero con {2}, y así sucesivamente. Aunque los dos tipos de datos que vamos a citar ahora, listas (list) y diccionarios (dict) los veremos más adelante en este manual, en ambos casos, tipos de datos que almacenan una colección de datos, esto es, más de uno (o ningún dato, None), podemos hacer aquí una referencia a ellos para ver cómo funcionan realmente la llamada a los argumentos del método. Vamos allá. No es necesario ni mucho menos obligatorio pasar como argumentos directamente los valores, bien fueran números o cadenas, habitualmente. Por el contrario, podemos tener una lista o un diccionario ya construido y llamar a los elementos o ítems que lo conforman, en el caso de las listas (list) bien por sus índices, que apuntan a la posición que ocupan en la secuencia, de izquierda a derecha si usamos índices positivos, siendo el índice que apunta al primer elemento el [0], el segundo [1], el tercero [2]; o bien, en el caso de los diccionarios, por el nombre que le hemos dado a los valores (se denominan claves (key), y forman parte de un par clave/valor, key/value, con la sintaxis clave:valor) a través del método dict.get(key) que nos devuelve el valor, value, asignada a esa misma clave. ¿Qué tal si vemos un ejemplo?

Que no nos atrape la desazón: repetimos que los tipos de datos lista y diccionario, con sus métodos respectivos, los estudiaremos más adelante y ya veremos cómo lo comprendemos todo mucho mejor.
Vamos a introducir aquí una nueva entrada que abunda y profundiza más en la vida y milagros del método str.format(*args, **kwargs), un método con muchísima enjundia que conviene conocer muy, muy bien. Lo etiquetaremos como T2 dado que contendrá elementos de cierta complejidad para los que todavía no estamos del todo preparados. Sin embargo, podemos echarle un vistazo al cabo de este apartado, como si lo hubiéramos etiquetado como T1 para que "nos vayan sonando campanas" puesto que lo usaremos en varias ocasiones con diferente gramática. De todas maneras es muy recomendable estudiarlo con tranquilidad al final de este manual.
T2. EL MÉTODO STR.FORMAT(*ARGS, **KWARGS) AL DESCUBIERTO.
8) STR.INDEX(SUBSTRING, ÍNDICE DE INICIO, INDICE FINAL):
Es un método muy similar a str.find(substring, índice de inicio, índice final) con la única diferencia de que devuelve ValueError si no encuentra la substring que hemos seleccionado, o su índice correspondiente si la encuentra.
En 1. y 2. hemos introducido como argumento una substring que el método ha encontrado e indexado devolviéndonos su índice, en el primer caso sin utilizar índices como argumentos opcionales, y en el segundo recurriendo a ambos.
En 3. hemos introducido una substring que no se halla en el espacio acotado por los índices de inicio y final. Como consecuencia, Python lanza una excepción.del tipo esperado: ValueError: substring not found, vamos, que hemos elegido un valor equivocado y por eso no encuentra la substring.
En 4. hacemos lo propio usando una substring con varios caracteres donde el método nos devuelve el índice correspondiente al primer carácter literal de la misma.
En los casos 5. y 6. recurrimos al método str.find(substring, índice de inicio, índice final) para comparar su funcionamiento con el método actual. Podemos ver como arroja resultados similares.
Finalmente, en 7., 8. y 9. hemos provocado un error intencionado para comprobar la reacción del método str.find(substring, índice de inicio, índice final) en comparación con str.index(substring, índice de inicio, índice final). En esta ocasión, el manejo de errores es distinto.
9) STR.ISALNUM():
Tenemos, como en el caso del método str.endswith(sufijo, índice de inicio, índice final), un método que devuelve valores booleanos (de hecho, todos los métodos que comienzan por 'is-' devuelven un booleano porque el prefijo 'is' hace referencia al operador de identidad (v. entrada LOS OPERADORES 'IS' E 'IN'. PERTENENCIA E IDENTIDAD, en este mismo apartado) y, en consecuencia, formula preguntas que se responden con True o False. Otra cosa que tienen en común es que no llevan argumentos). Devolverá True si la cadena contiene caracteres alfanuméricos, y False si no es así. Y de ahí su nombre: ¿IS ALPHABETICAL AND NUMERAL? IS-AL-NUM. Y olé.
¡Ojo! Cada carácter es alfanumérico y no si en la string hay a la vez caracteres alfabéticos ("a", "b", "c", "d",...) y numéricos ("1", "2", "3", "4",...).
Es un argumento que no lleva argumento alguno y que se pasa en vacío:
En nuestro ejemplo, podemos comprobar que la string debe ser un todo continuo, un texto único literario sin espacios en blanco intermedios, pues si no es así devolverá False. Así mismo, no admite caracteres que no sean alfabéticos y numéricos: la inserción de signos ortográficos categoriza a la cadena si le pasamos el método como False.
10) STR.ISALPHA():
Es un método muy parecido con el anterior. Como ya sabemos, opera con booleanos. En este caso devuelve True si todos los caracteres en la cadena son alfabéticos, y False si encuentra alguno que no lo sea. También se aplica una única string y no lleva argumento alguno en el paréntesis.
Como vemos en el último caso, se permite la alternancia entre mayúsculas y minúsculas, del mismo modo en que lo hace el método anterior.
11) STR.ISDECIMAL():
Continuamos con los métodos booleanos de las strings. Devuelve True cuando todos los caracteres que integran la cadena son dígitos. Sin embargo, este método tiene la particularidad de que sólo es aplicable a strings sujetas a un esquema de codificación Unicode. Para ello debemos anteponer a la comilla de apertura de la string el prefijo 'u' para asegurarnos de ello aunque, como podemos deducir a partir del ejemplo, no es estrictamente necesario.
12) STR.ISDIGIT():
Devuelve True cuando todos los caracteres de una cadena son dígitos. Como podemos ver es un método prácticamente idéntico a str.isdecimal(). Tengamos en cuenta que un dígito que tiene la propiedad "numeric_type"puede tener dos valores: dígito y decimal.
13) STR.ISLOWER():
Devuelve True en caso de que todos los caracteres de una string estén escritas en minúsculas y False si encuentra algún carácter en mayúscula.
14) STR.ISSPACE():
Este nuevo método devuelve True si la string contiene, al menos, un carácter o espacio en blanco, pero ningún otro carácter más:
15) STR.ISTITLE():
Este método devolverá True siempre y cuando todos los elementos de una string comiencen en mayúsculas, y False en caso contrario.
Como podemos ver, no tiene en cuenta la numeración (no existen números escritos en mayúsculas o en minúsculas: son sólo dígitos).
16) STR.JOIN(ITERABLE):
Devuelve una cadena en la que los caracteres de la string "matriz" se intercalan, se unen ("to join", "unir"), entre las cadenas de la secuencia (iterable) que le pasemos como argumento. Nos suena a chino, ¿verdad? Es un método que vamos a explicar con un esquema primero y, después, con un ejemplo.
Ahora, ponemos el ejemplo:
A que se entiende un poco mejor, ¿verdad?
Vamos a aprovechar para poner el foco en un par de cosas que conviene tener en cuenta.
Existen un buen puñado, la verdad. Como tales métodos existen todavía algunos más que no vamos a recoger aquí, porque su uso es muy específico, restringido o muy poco frecuente y no aparecen o no se usan en el 99.9% de las ocasiones. Prescindiremos de ellos.
Un método es una función (hace cosas, produce un resultado, ejecuta una acción concreta) y, en consecuencia, muestra una estructura sintáctica similar, con sus paréntesis reglamentarios al cabo del nombre de la función, lleven o no parámetros.
Por otra parte, y adelantándonos en unos cuantos capítulos al concepto de LIBRERÍA de Python, los métodos parecen que, en el caso de las cadenas que nos ocupan ahora, provinieran de una especie de librería propia, característica, exclusiva, de las strings y que el lenguaje, apoyándose en un criterio de mayor usabilidad y eficiencia para nosotros, programadores, en el momento de codificar, hubiera decidido prescindir de las sintaxis de importación de librerías y proporcionarles una categorización propia (métodos) para facilitar el acceso a los mismos.
Vaya tela, ¿verdad? Imaginemos que trabajamos en una famosa pizzería con más de 20 pizzas a la carta y que somos los cocineros (programadores) expertos en preparar suculentas pizzas (programas). Por una de esas casualidades de la vida resulta que nueve de cada diez clientes (personas que nos piden que les programemos algo) que acuden a nuestro restaurante (estudio de programación, o algo así) nos piden las mismas 5 0 6 clases de pizza, bien porque sean las más baratas, las más sabrosas, las mejor recomendadas o por una mezcla de todos estos motivos. Y, también casualmente, resulta que esas mismas pizzas utilizan más o menos los mismos ingredientes (funciones: la función "queso", la función "tomate", la función "albahaca", la función "anchoa", etc,). Vista la situación, nuestro gestor de empresa (Python) echa cuentas y nos dice:"Vamos a ver: Como parece que todas las pizzas que preparamos son las mismas y con los mismos ingredientes a éstos, en concreto a éstos(la función "queso", la función "tomate", la función "albahaca", la función "anchoa", etc,), en lugar de almacenarlos junto a los demás en el enorme depósito que tenemos cuatro pisos más abajo (librerías) de la cocina, como se utilizan más y se consumen más rápido, conviene tenerlas más a mano. Así que vamos a recoger todos estos ingredientes, los etiquetamos (métodos) y los ponemos más a manos, en la despensa que tenemos justo en la puerta de al lado (funciones integradas de Python de acceso rápido)".
Y así todos contentos.
¿Lo entendemos mejor así?
 |
| VERODE EN FASE DE FLORACIÓN |
Como conclusión antes de pasar a estudiar los métodos debemos saber que la Programación Orientada a Objetos, POO por sus siglas en castellano, en la que también se apoya Python y la gran mayoría de los lenguajes de programación modernos. (Sobre la POO hablaremos al comienzo del segundo manual de Python) utiliza los objetos, y recordemos que para Python TODO son objetos, que son entidades que tienen un determinado estado, un comportamiento (método) específico y, cómo no, una identidad particular en sus interacciones, para diseñar aplicaciones y programas informáticos (tomado de la WIKIPEDIA). De la POO Python incorpora para llamar a los métodos una sintaxis que la distingue:
nombre_objeto.nombre_método(parámetros)
La clave del asunto se encuentra en el elemento más ínfimo de la fórmula anterior: el punto que separa a nombre_objeto de nombre_método(parámetros) y que en Python se denomina OPERADOR DE PUNTO u OPERADOR PUNTO. ¿Operador de qué? ¿Sobre qué opera? Pues de ACCESO A ATRIBUTO. ¿Y qué significa esto? Que el punto nos permite tener acceso a los atributos/propiedades y a los métodos de un objeto determinado. A su vez, tengamos en cuenta que un atributo/propiedad y un método son, al mismo tiempo, objetos que, como tales objetos, pueden tener sus propios atributos/propiedades y sus propios métodos. Y estos también los suyos, y así sucesivamente "ad infinitum". A todo esto, desde lo más genérico hasta lo más concreto, hasta el atributo/propiedad y/o método deseados, podemos llegar a través del punto, utilizando todos los OPERADORES DE PUNTO necesarios para conseguir ese atributo/propiedad o método que andamos buscando. A esto es lo que se llama DOT METHOD o DOT NOTATION, esto es, "MÉTODO DE PUNTO" o "NOTACIÓN DE PUNTO".
 |
 |
| ALTOS DE CANDELARIA, SURESTE DE TENERIFE |
LISTADO DE MÉTODOS DE LAS STRINGS:
1) STR.CAPITALIZE():
Estudiemos su sintaxis porque va a ser la misma para todos los métodos, tanto de las strings como para el resto de tipos de datos: str indica que en la posición que antecede al operador de punto debemos colocar el nombre de la variable en la que hemos almacenado la cadena (si x = "manzana" escribimos x.capitalize()). A continuación recurrimos a la notación de punto y escribimos uno a continuación del nombre de la variable lo que nos permite tener acceso al método. Finalmente, escribimos el nombre del método deseado, en nuestro caso, capitalize().
Este primer método de las strings nos devuelve la misma string pero con el primer carácter de la cadena, el correspondiente al índice 0, str[0], en mayúsculas que es, mira por dónde, lo que significa en castellano "capitalize".
En este caso, la función no lleva parámetros por lo que no le pasamos argumento alguno, como ya nos advierte el cuadro de ayuda d Python.
Cuando vamos a trabajar con un método y dado que el intérprete de Python domina que es un primor su propia sintaxis, como no puede ser de otra manera, en cuanto detecta que hemos declarado un objeto, en el caso que nos ocupa, una string, aunque de igual forma sucede con una lista, unta tupla, un diccionario, etc, esto es, cualquier objeto que disponga de métodos asociados (no todos los tipos de datos en Python los tienen: INT y FLOAT, por ejemplo, no tienen métodos), y a continuación recurrimos al operador de punto, vamos, que escribimos un modesto punto a la derecha del nombre del objeto, automáticamente Python destaca un cuadro de ayuda donde nos muestra un listado en orden alfabético de todos los métodos habilitados para ese tipo de dato. Veámoslo aquí:
Este primer método de las strings nos devuelve la misma string pero con el primer carácter de la cadena, el correspondiente al índice 0, str[0], en mayúsculas que es, mira por dónde, lo que significa en castellano "capitalize".
 |
Cuando vamos a trabajar con un método y dado que el intérprete de Python domina que es un primor su propia sintaxis, como no puede ser de otra manera, en cuanto detecta que hemos declarado un objeto, en el caso que nos ocupa, una string, aunque de igual forma sucede con una lista, unta tupla, un diccionario, etc, esto es, cualquier objeto que disponga de métodos asociados (no todos los tipos de datos en Python los tienen: INT y FLOAT, por ejemplo, no tienen métodos), y a continuación recurrimos al operador de punto, vamos, que escribimos un modesto punto a la derecha del nombre del objeto, automáticamente Python destaca un cuadro de ayuda donde nos muestra un listado en orden alfabético de todos los métodos habilitados para ese tipo de dato. Veámoslo aquí:
 |
2) STR.CENTER(ANCHO, CARÁCTER DE RELLENO):
Este método nos permite centrar una string entre un carácter (uno sólo) que elijamos, a la izquierda y a la derecha de nuestra cadena.
Como argumentos lleva, primero, el largo total de la cadena. Llama la atención que, en el cuadro de ayuda en lugar de 'length', cuya contracción, 'len', representa el nombre de la función len() ya conocida por nosotros y que nos devuelve la longitud de una cadena, se sustituya aquí por 'width'. Esto es así porque el 'width' determina el ancho/largo que nosotros le queremos dar a la cadena, y no al ancho/largo que tenga por sí misma y que podemos calcular a través de la función len(). tal y como se verá en los ejemplos. Si el len() de la string fuera igual al 'width' que proponemos no tendría sentido añadir ningún carácter de relleno para centrar la cadena en tanto que no sobra espacio alguno ni a derecha ni a izquierda; y segundo, el carácter que hayamos seleccionado para rellenar a la derecha y a la izquierda de la cadena para centrar nuestra string.
Ambos elementos, como ocurre con todos los diferentes argumentos que se pasan a una función, deben ir separados por comas.
Una buena práctica pasa por calcular previamente la longitud de nuestra string apoyándonos en la función len() que conocemos bien, y determinar cuántos caracteres queremos añadir a ambos lados. Podemos calcular los que queremos tener a la izquierda, lo multiplicamos por dos para incluir los de la derecha y, finalmente, esta cantidad se la sumamos a la devolución de la función. La cifra que obtengamos será la que pasemos como primer argumento del método:
 |
3) STR. COUNT(SUB, ÍNDICE DE INICIO, ÍNDICE FINAL):
Este método como sugiere su nombre, tiene por cometido "contar". ¿Y qué cuenta? Pues las substrings (sub) iguales que existen entre el índice de inicio (start) y el índice final (end). Por eso, como argumentos lleva la substring que queremos contar, bien sea un único carácter literal o una substring formada por n caracteres literarios (donde n es cualquier número entero), desde dónde debe empezar a contar (índice de inicio) y hasta dónde debe hacerlo (índice final), con los argumentos separados por comas.
éste método es muy útil. por ejemplo, para localizar el número de veces que se repite una palabra o un signo en un texto, cualquiera que sea su longitud.
 |
 |
| FLORACIÓN Y NIEBLA EN EL MONTE DEL AGUA, NOROESTE DE TENERIFE. |

En el cuadro de ayuda se muestra un listado completo de todos los métodos asociados a las strings. Pero en este capítulo no nos vamos a ocupar de todos ellos. Los que se expongan a continuación son los más habituales, los de uso más frecuente y que conviene conocer mejor. Incluso se introducirá alguno que se complementará a posteiori con una entrada aparte por su importancia y profundidad a la hora de mejorar nuestros códigos. Los que no se incluyan aquí serán aquéllos que tengan un uso mucho más restringido y/o exclusivo. Aún así, dispondrán de sus propia entrada para que, al menos, nos hagamos una idea de ellos.
4) STR.ENDSWITH(SUFIJO, ÍNDICE DE INICIO, ÍNDICE FINAL):
Éste nuevo método, que puede traducirse líbremente como "termina con...", trabaja con booleanos. Devuelve True si nuestra string acaba con el sufijo (suffix) que le hayamos pasado previamente como argumento. Podemos utilizar los índices de inicio y final (start y end) para restringir la búsqueda del intérprete a un pedazo concreto de la string. Su uso es optativo, a menos que queramos acotar explícitamente una secuencia de la string.
 |
| C56 |

No dejemos de consultar la entrada dedicada a los tipos de datos None y Booleano: Nos ayudará a tener las ideas mucho más claras a la hora de entender bien éste y otros métodos de las strings. Es un consejo de amigo perruno, ¿eh?.
Un aspecto a tener en cuenta es el concepto pythoniano de "sufijo" (suffix). Básicamente, Python entiende por ello la terminación de una string, ya sea éste un único carácter literal, una palabra completa en un texto o un conjunto heterogéneo de caracteres literarios o substrings. La única condición que debe cumplir indefectiblemente para que el intérprete de Python lo considere como un sufijo hecho y derecho es que esté al final de la string.
Mostramos un ejemplo para entenderlo mejor.
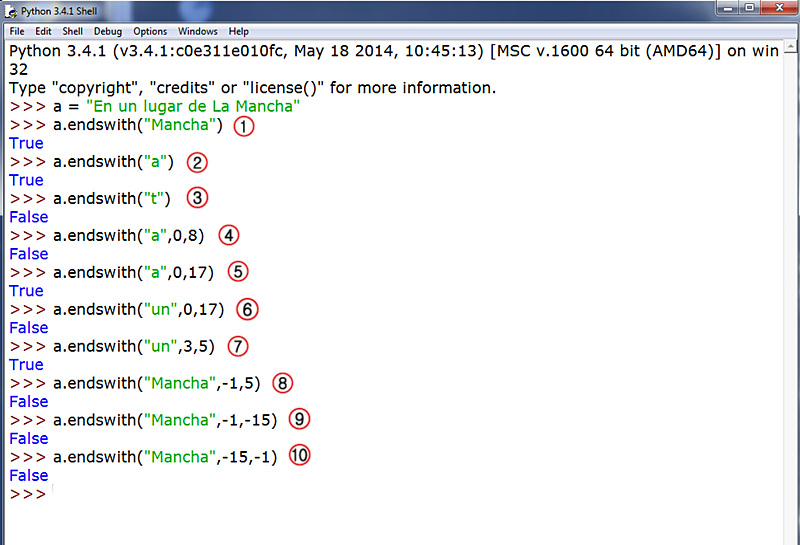 |
- En esta string que, como vemos, es un texto literario completo, hemos introducido como sufijo "Mancha", sin acotar la substring entre índices de inicio y final. El intérprete la busca, detecta que es la última, que no hay más caracteres literarios a partir de la 'a' final de "Mancha" y nos devuelve True.
- En esta ocasión pedimos un único carácter literario, la 'a'. El intérprete analiza nuestra petición y comprueba que este carácter es, precisamente, el último de toda la string "En un lugar de La Mancha". Tampoco hemos introducido aquí ningún índice de inicio y final. Nos devuelve True. Hubiera sucedido igual si hubiéramos solicitado 'ha', 'cha', 'ncha', etc.
- Devuelve False porque la 't' no está al final de la string. De hecho, ni siquiera existe.
- Volvemos a pedir 'a', pero ésta vez incluimos unos prefijos, de 0 a 8. Este trozo o substring se corresponde con el siguiente texto: "En un lu" (recordemos que el carácter señalado por el índice final no se cuenta). Pues bien, dado que 'a' no es el sufijo de la substring sino 'u', el intérprete de Python nos devuelve False.
- En cambio, aquí sí obtenemos True porque la substring que acotamos con el índice de inicio y final se corresponde con la substring "En un lugar de La" que, precisamente, esta vez sí, en 'a'.
- Evidentemente. False. La substring 'un' si está presente en la subcadena acotada entre los índices 0 y 17, pero no es el sufijo de la misma.
- Sin embargo, 'un' sí pasa a convertirse en sufijo cuando acotamos hasta 5.
- 9. 10. En estos tres casos hemos recurrido a índices negativos y hemos obtenido como resultado False. Pero observemos el siguiente y último ejemplo:
 |
 |
En el tercer caso hemos omitido el índice de inicio pero no el índice final. Pero Python no admite, sintácticamente hablando, el dejar un espacio vacío entre comas, el que correspondería al índice de inicio. Con ello, "subrepticiamente" nos obliga a incluir siempre, como mínimo, el índice de inicio en el caso de recurramos a los índices para acotar una substring.
Pero existe, sin embargo, una manera de solventarlo: usando el objeto None, que como sabemos si hemos leído la entrada correspondiente, es un tipo de dato de Python que significa, resumidamente, "ninguna cosa", pasado como índice de inicio. Veámoslo con un ejemplo:
 |
En el último caso, podemos comprobar una vez más la sensibilidad de Python al uso de mayúsculas y minúsculas.
Proponemos una entrada nueva:
T1. LOS OPERADORES 'IN' E 'IS'. PERTENENCIA E IDENTIDAD.
 |
| VISTA DEL BOSQUE DE LAURISILVA SECA DE GÜÍMAR DESDE LAS VENTANAS DE UN TÚNEL DE CONDUCCIÓN DE AGUA, VALLE DE GÜÍMAR, CENTRO-SUR DE TENERIFE |
5) STR.EXPANDTABS(TABSIZE=8):
Aquí tenemos un método peculiar. Su función consiste en devolver una copia de nuestra string de tal modo que los espacios de tabulación (separación) van siendo ocupados por caracteres de nuestra string hasta rellenar, si es necesario, todo el espacio de tabulación.
Dicho esto, vamos por partes: para que esto ocurra, debemos decirle a Python que nuestra string está tabulada porque queremos que la separación entre una substring y otra substring diferente sea de n espacios. ¿Y cómo se lo decimos? Pues con otro escape... El escape '\t'.
Vamos a ver qué hace este nuevo escape:
- \t => Permite separar las strings o substrings una distancia determinada, por defecto, de 8 espacios en blanco (de aquí 'tabsize=8', "ancho de la tabulación") entre unas y otras.
Por otra parte, de acuerdo a la longitud de la substring (la devolución de su 'len()', o si lo preferimos, su número total de caracteres, que es lo mismo), éstas van ocupando los espacios en blanco que indiquemos en el tabsize dejando el resto sin rellenar. Tengamos en cuenta que el separador no se cuenta.
Para ver el resultado de manera correcta debemos acudir a la función print().
Podremos entender mejor las cualidades del método si lo vemos con un ejemplo:
 |
En los casos 2. y 3. hemos hecho lo propio modificando el tabsize a nuestro gusto. Notemos cómo las strings van "comiendo" espacios hasta completar el tamaño de la tabulación.
En el ejemplo 4. hemos introducido un entero negativo (obsta decir que ni se nos ocurra introducir un decimal si no queremos que Python nos lance una excepción). Aquí ya no hay tabulación que valga. Aunque Python no nos da error en tanto que hemos pasado un entero, al ser éste negativo, se anula el método y la separación entre los caracteres se reduce a un único espacio en blanco, independientemente del ancho de las subcadenas.
Por último, en el caso 5., hemos querido pasar como argumento una expresión aritmética simple. Comprobamos que la devolución coincide exactamente con la del ejemplo 3. En ambos casos, el tabsize es igual a 12.
Para finalizar, hemos dejado a la vista el cuadro de ayuda del método donde podemos ver que la tabsize que incluye por defecto es igual a 8 espacios en blanco, la misma que '\t'.
 |
Acabamos con la explicación del método aportando un ejemplo más, con frutas, para hacernos más dulce el trago de tanta tabulación. El ejemplo final demuestra de una manera gráfica cómo cuenta el intérprete de Python el tabsize o '\t'.
 |
 |
| LAURISILVA EN LA CRUZ DEL CARMEN. ANAGA OCCIDENTAL |
6) STR.FIND(SUBSTRING, ÍNDICE DE INICIO, ÍNDICE FINAL):
Con este nuevo método podemos encontrar ("to find", "encontrar") el índice que corresponde a una substring, dentro de una string, que pasemos como argumento. Del mismo modo que hemos visto en métodos anteriores, la inclusión de un índice de inicio y/o un índice final es opcional, con el propósito de acotar un espacio estimado donde rastrear. Si solicitamos la búsqueda de una substring que se repite más de una vez, Python nos devuelve el índice del primer lugar donde la encuentre bajo la premisa "primera identificación de la substring => índice". Esto sucederá así a menos que acotemos el espacio de búsqueda de la substring en un espacio distinto.
Cuando la substring esté compuesta por más de un carácter, Python devolverá el índice del primer carácter, pero no los índices de inicio y final de la substring que pasamos como argumento: nos devuelve un int que apunta a un índice específico pero no una slice, con sus índices de inicio y final.
 |
Si el método no encuentra lo que le pedimos devuelve -1.
En el ejemplo que mostramos a continuación empatamos una verificación mediante el recurso al operador de pertenencia, para saber de antemano si tal substring está presente en una string dada, con el método str.find(...) para localizarla, en el caso de que el verificador devuelva True, por el índice de su primer carácter:
 |
7) STR.FORMAT(*ARGS, **KWARGS):
Este método que traemos ahora aquí es bastante más singular en su funcionalidad que lo que hemos visto hasta ahora. Básicamente, el método str.format(*args, **kwargs) ejecuta un "formateo de salida de datos", un "DISPLAY", una forma de presentar el resultado de la ejecución de un script o programa a la vista del usuario. La string que recibe este método incorpora lo que podemos llamar un CAMPO DE REEMPLAZO que queda delimitado de manera gráfica mediante llaves: {...}.
Cada campo de reemplazo o de sustitución puede contener dos tipos de datos: el índice de un argumento posicional (*args), o el nombre de una palabra reservada, keyword, (**kwargs). La ejecución del método devuelve una copia de la string original donde cada campo de reemplazo, ya que pueden coexistir varios de ellos, los que queramos, dentro de una misma string se sustituye por el valor que le corresponda.
¿A que no nos enteramos de nada, eh? Claro, es que dicho así... ¿Qué tal si ponemos un ejemplo para entender mejor de qué va la cosa? Venga.
 |
Podemos comprobar cómo los campos de reemplazo pueden ser números, expresiones (recordemos que una expresión representa a su propia devolución, esto es, 4 + 5, por ejemplo, representa al int 9), strings, etc.
Este método, entre otros procesos, resulta muy útil en operaciones complejas en las que tenemos con trabajar con un número indeterminado de variables desconocidas, por ejemplo, las que almacenes los inputs de usuarios a preguntas del programa, como: "Introduzca un número entre 0 y 10".
 |
Aquí tenemos otro ejemplo más de uso del método que estamos tratando con la inclusión en el segundo campo de reemplazo de una keyword (kwarg), en esta ocasión, una vieja conocida nuestra: la función type().
Para finalizar, un dato importante: los campos de reemplazo deben ser números enteros. Aunque Python reconoce el orden alfabético donde "a" va primero, "b" después, "c" a continuación y así sucesivamente, el método no admite el uso de caracteres alfabéticos en los campos.
 |
| CULANTRILLO SOBRE LA ROCA EN UN NACIENTE DEL ACANTILADO DE LA CULATA, BOSQUES DE LA ISLA BAJA, CONCRETAMENTE EN LOS ALTOS DE ICOD, NOROESTE DE TENERIFE |
Como ya hemos visto, resulta fundamental el orden en que pasemos los argumentos en str.format(), de tal modo que el primer argumento se corresponde con {0}, el segundo argumento con {1}, el tercero con {2}, y así sucesivamente. Aunque los dos tipos de datos que vamos a citar ahora, listas (list) y diccionarios (dict) los veremos más adelante en este manual, en ambos casos, tipos de datos que almacenan una colección de datos, esto es, más de uno (o ningún dato, None), podemos hacer aquí una referencia a ellos para ver cómo funcionan realmente la llamada a los argumentos del método. Vamos allá. No es necesario ni mucho menos obligatorio pasar como argumentos directamente los valores, bien fueran números o cadenas, habitualmente. Por el contrario, podemos tener una lista o un diccionario ya construido y llamar a los elementos o ítems que lo conforman, en el caso de las listas (list) bien por sus índices, que apuntan a la posición que ocupan en la secuencia, de izquierda a derecha si usamos índices positivos, siendo el índice que apunta al primer elemento el [0], el segundo [1], el tercero [2]; o bien, en el caso de los diccionarios, por el nombre que le hemos dado a los valores (se denominan claves (key), y forman parte de un par clave/valor, key/value, con la sintaxis clave:valor) a través del método dict.get(key) que nos devuelve el valor, value, asignada a esa misma clave. ¿Qué tal si vemos un ejemplo?

Que no nos atrape la desazón: repetimos que los tipos de datos lista y diccionario, con sus métodos respectivos, los estudiaremos más adelante y ya veremos cómo lo comprendemos todo mucho mejor.
Vamos a introducir aquí una nueva entrada que abunda y profundiza más en la vida y milagros del método str.format(*args, **kwargs), un método con muchísima enjundia que conviene conocer muy, muy bien. Lo etiquetaremos como T2 dado que contendrá elementos de cierta complejidad para los que todavía no estamos del todo preparados. Sin embargo, podemos echarle un vistazo al cabo de este apartado, como si lo hubiéramos etiquetado como T1 para que "nos vayan sonando campanas" puesto que lo usaremos en varias ocasiones con diferente gramática. De todas maneras es muy recomendable estudiarlo con tranquilidad al final de este manual.
T2. EL MÉTODO STR.FORMAT(*ARGS, **KWARGS) AL DESCUBIERTO.
8) STR.INDEX(SUBSTRING, ÍNDICE DE INICIO, INDICE FINAL):
Es un método muy similar a str.find(substring, índice de inicio, índice final) con la única diferencia de que devuelve ValueError si no encuentra la substring que hemos seleccionado, o su índice correspondiente si la encuentra.
 |
En 1. y 2. hemos introducido como argumento una substring que el método ha encontrado e indexado devolviéndonos su índice, en el primer caso sin utilizar índices como argumentos opcionales, y en el segundo recurriendo a ambos.
En 3. hemos introducido una substring que no se halla en el espacio acotado por los índices de inicio y final. Como consecuencia, Python lanza una excepción.del tipo esperado: ValueError: substring not found, vamos, que hemos elegido un valor equivocado y por eso no encuentra la substring.
En 4. hacemos lo propio usando una substring con varios caracteres donde el método nos devuelve el índice correspondiente al primer carácter literal de la misma.
En los casos 5. y 6. recurrimos al método str.find(substring, índice de inicio, índice final) para comparar su funcionamiento con el método actual. Podemos ver como arroja resultados similares.
Finalmente, en 7., 8. y 9. hemos provocado un error intencionado para comprobar la reacción del método str.find(substring, índice de inicio, índice final) en comparación con str.index(substring, índice de inicio, índice final). En esta ocasión, el manejo de errores es distinto.
9) STR.ISALNUM():
Tenemos, como en el caso del método str.endswith(sufijo, índice de inicio, índice final), un método que devuelve valores booleanos (de hecho, todos los métodos que comienzan por 'is-' devuelven un booleano porque el prefijo 'is' hace referencia al operador de identidad (v. entrada LOS OPERADORES 'IS' E 'IN'. PERTENENCIA E IDENTIDAD, en este mismo apartado) y, en consecuencia, formula preguntas que se responden con True o False. Otra cosa que tienen en común es que no llevan argumentos). Devolverá True si la cadena contiene caracteres alfanuméricos, y False si no es así. Y de ahí su nombre: ¿IS ALPHABETICAL AND NUMERAL? IS-AL-NUM. Y olé.
¡Ojo! Cada carácter es alfanumérico y no si en la string hay a la vez caracteres alfabéticos ("a", "b", "c", "d",...) y numéricos ("1", "2", "3", "4",...).
Es un argumento que no lleva argumento alguno y que se pasa en vacío:
 |
 |
 |
| HIJA, ÁRBOL PROPIO DE LA LAURISILVA HÚMEDA. LA CRUZ DEL CARMEN EN DIRECCIÓN A LAS CARBONERAS, ANAGA, TENERIFE |
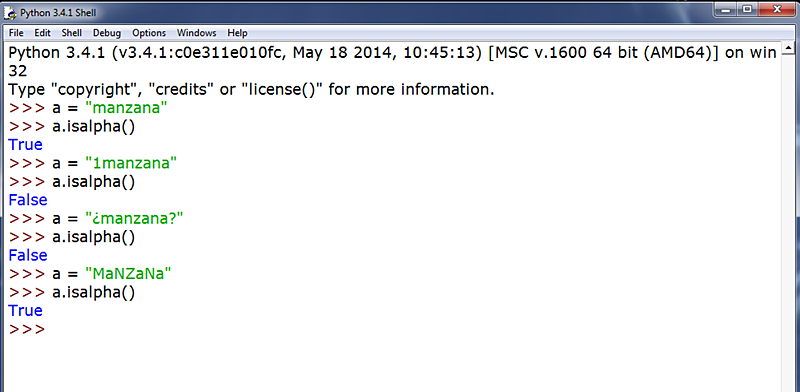
10) STR.ISALPHA():
Es un método muy parecido con el anterior. Como ya sabemos, opera con booleanos. En este caso devuelve True si todos los caracteres en la cadena son alfabéticos, y False si encuentra alguno que no lo sea. También se aplica una única string y no lleva argumento alguno en el paréntesis.
 |
11) STR.ISDECIMAL():
Continuamos con los métodos booleanos de las strings. Devuelve True cuando todos los caracteres que integran la cadena son dígitos. Sin embargo, este método tiene la particularidad de que sólo es aplicable a strings sujetas a un esquema de codificación Unicode. Para ello debemos anteponer a la comilla de apertura de la string el prefijo 'u' para asegurarnos de ello aunque, como podemos deducir a partir del ejemplo, no es estrictamente necesario.
 |
Devuelve True cuando todos los caracteres de una cadena son dígitos. Como podemos ver es un método prácticamente idéntico a str.isdecimal(). Tengamos en cuenta que un dígito que tiene la propiedad "numeric_type"puede tener dos valores: dígito y decimal.
 |
13) STR.ISLOWER():
Devuelve True en caso de que todos los caracteres de una string estén escritas en minúsculas y False si encuentra algún carácter en mayúscula.
 |
Este nuevo método devuelve True si la string contiene, al menos, un carácter o espacio en blanco, pero ningún otro carácter más:
 |
Este método devolverá True siempre y cuando todos los elementos de una string comiencen en mayúsculas, y False en caso contrario.
 |
 |
| POLIPODIO. VARIEDAD DE HELECHO DE PEQUEÑAS DIMENSIONES PROPIO DE LOS HUMEDALES DE LA LAURISILVA. |
Devuelve una cadena en la que los caracteres de la string "matriz" se intercalan, se unen ("to join", "unir"), entre las cadenas de la secuencia (iterable) que le pasemos como argumento. Nos suena a chino, ¿verdad? Es un método que vamos a explicar con un esquema primero y, después, con un ejemplo.
 |
 |
Vamos a aprovechar para poner el foco en un par de cosas que conviene tener en cuenta.
- Un elemento es ITERABLE cuando se puede repetir (iterar) en modo de secuencia para conseguir un resultado. Por eso, 'b' es iterable ya que podemos añadir todas las cadenas que queramos. Profundizaremos en y perfilaremos mejor el concepto de ITERACIÓN cuando tratemos el tema de las SEQUENCES (SECUENCIAS).
- Tenemos que usar en 'b' paréntesis para poder aglutinar en una única variable una secuencia de datos: "a", "b", "c", "d", "manzana", "pera", etc... dado que cada una de ellas es una string (o substring) en sí mismas.
- Y para que el intérprete de Python los reconozca como tales, debemos separar las cadenas mediante comas.
'LJUST' es una contracción de los términos "Left", "izquierda", y "JUSTified", "justificado", en conjunto, "justificado a la izquierda", lo que ya nos advierte de por dónde van los tiros. Este método consiste en añadir a la izquierda de la string tantos caracteres de relleno (eso es lo que significa "FILLCHAR", que es a su vez la contracción de "FILL => "to fill", "rellenar" y "CHARacter", "carácter") como indiquemos en el WIDTH, en el ancho, que le pasemos a la función como argumento, teniendo en cuenta que el ancho comienza a contarse a partir del primer carácter (str[0]) de la cadena. Esto significa que si el "WIDTH" que le pasemos al método coincide con el resultado de aplicarle la función len(str). esto es, WIDTH = len(str), el método nos devolverá una copia exacta de la cadena, sin justificado alguno. Este FILLCHAR, por defecto, es un espacio en blanco, pero podemos sustituirlo por el carácter que mejor nos convenga.
 |
18) STR.LOWER():
Este nuevo método podría entenderse como un complemento de str.islower(), en tanto que elimina las mayúsculas de una string sustituyéndolas por minúsculas. Resulta un método muy útil, por ejemplo, que una dirección de correo electrónico, que normalmente se escribe en minúsculas, no incluya mayúsculas por error.
 |

Aprovechamos la ocasión para re-asentar un aspecto de los métodos que ya hemos declarado más arriba: los métodos que "tendrían" que pasar como argumentos el propio nombre de la cadena, sin añadir ningún otro argumento más, tan sólo el nombre de la variable que la almacena, muestran un argumentado vacío para no incurrir en reiteraciones innecesarias (economía) que, encima, pudiera suscitar algún tipo de conflicto con el intérprete de Python. Esta norma, por así decirlo, nos ayudará a dilucidar en caso de duda (aunque para eso siempre estará a nuestra disposición, en nuestro IDLE, claro, los cuadros de información pertinentes) qué métodos llevan argumentos y cuáles no: son aquéllos que responden a una pregunta que se responde con un booleano y no a aquéllos otros, salvo excepciones como str.capitalize() o el que acabamos de ver, str.lower(), que "hacen algo"... ¡A mí también me gustan las galletas!
19) STR.LSTRIP(CHARS):
Con este nuevo método podemos suprimir de una string su primer carácter o sus primeros caracteres, devolviéndonos una cadena nueva con la ausencia de los caracteres pasados como argumentos. Insistimos nuevamente en que Python, aplicando el CASE SENSITIVE que ya debe sonarnos, discrimina entre mayúsculas y minúsculas.
 |
Este método permite separar, sustraer, encapsular entre comas una porción de la string original generando una substring separada de la porción anterior y posterior de la cadena de texto a la que pertenece.
 |
 |
| SUBESPECIE DE TABAIBAS DULCES RASTRERAS SOBRE MALPAÍS (SUELOS ROCOSOS DERIVADOS DE LAVAS DENSAS, RÁPIDAMENTE SOLIDIFICADAS, CON ESCASA EROSIÓN Y MORFOLOGÍA POLIÉDRICA) EN LAS COSTAS DE TAJAO, ARICO, SUR DE TENERIFE. |
21) STR.REPLACE(OLD, NEW, COUNT):
Con el método que mostramos a continuación podemos sustituir una string ("OLD", "vieja") por otra nueva ("NEW"). Si añadimos un entero en "COUNT", "conteo", su valor determinará el número de veces que el método sustituya la string vieja por la nueva, en orden de izquierda a derecha.
 |
22) STR.RFIND(SUB, START, END):
La aplicación del método devuelve un entero, int, que se corresponde con el último índice donde Python localiza la substring que hemos pasado como argumento. Podemos, si queremos, restringir la búsqueda incluyendo entre los paréntesis un índice de inicio ("START") y un índice final ("END"). En caso de no existir tal subcadena, o que ésta no se encuentre entre los índices que le pasamos al método, nos devolverá el valor -1, de manera análoga al método str.find(substring, índice de inicio, índice final) que ya estudiamos:
 |
23) STR. RINDEX(SUB, START, END):
Se trata de un método muy similar al anterior con la única diferencia de que, en lugar de devolver -1 cuando no encuentra la substring, lanza una excepción del tipo ValueError.
 |
24) STR. RJUST(WIDTH, FILLCHAR):
Este método es el complementario perfecto de str.ljust(width, fillchar). Hace exactamente lo mismo, sólo que si aquél lo hacía a la izquierda, éste hace lo propio por la derecha ("Right JUSTified"). Debemos proporcionar el ancho y el carácter que queremos usar como relleno.
 |
25) STR.RPARTITION(SEP):
Es un método similar a str.partition(sep) salvo que en lugar de establecer la separación entre la cabeza ("HEAD") y la cola ("TAIL") la primera vez que encuentra el carácter o substring que lle hemos pasado como separador ("SEP"), lo hace con el último.
 |
26) STR.SPLIT(SEP=NONE, MAXSPLIT=-1):
En castellano, "SPLIT" significa ·escisión", "división", "ruptura", lo cual ya nos advierte de por dónde van los tiros con el método que presentamos a continuación. A partir de un separador, "SEP", que como nos indica el texto descriptivo es, por defecto, None que, recordemos, se trata de un objeto, de un tipo de dato que apunta a "ninguna cosa" (v. entrada), podemos introducir una substring que separará la cadena original en dos partes: la anterior al separador y la posterior, eliminando al separador en sí, que desaparece en la devolución final.
Si no utilizamos separador alguno o pasamos None como argumento, se producirá una división de todas las substrings. utilizando los espacios/caracteres en blanco como separadores.
El argumento opcional "MAXSPLIT", que podemos traducir líbremente como "número máximo de cortes", apunta al número de divisiones que queremos efectuar.
En suma, es un método con claras concomitancias con str.partition(sep) o str.rpartition(sep), salvo que elimina el separador del resultado. Otra diferencia a destacar es que nos muestra los resultados como un objeto de tipo lista, list, [ ], y no como un objeto de tipo tupla, tuple, ( ), como ocurre con los dos métodos anteriormente mencionados lo que, subsecuentemente, afecta a su mutabilidad, aspecto éste que estudiaremos en el capítulo siguiente.
 |
 |
| FLOR DEL ALMENDRO. ALMENDRALES SILVESTRES ENTRE LAS ZONAS DE TAMAIMO Y CHÍO, COMARCA DE ISORA, OESTE DE TENERIFE |
27) STR.RSPLIT(SEP=NONE, MAXSPLIT=-1):
Exactamente lo mismo que el método anterior salvo que comienza a contar de derecha, ("R", de right") a izquierda si pasamos "MAXSPLIT" como argumento del método, en lugar de hacerlo de izquierda a derecha.
 |
28) STR.SPLITLINES(KEEPENDS):
Si no se le pasa un argumento, este método devuelve la string original encapsulada entre corchetes, [ ], esto es, convierte nuestra string en un elemento o ítem de una lista, list, incluyendo los saltos de línea, que interpreta como substrings y, en consecuencia, como elementos o ítems diferenciados de una lista.
Si pasamos un número (un entero, int, siempre un entero. No lo olvidemos) como argumento, el método nos mostrará los "KEEPENDS", los "finales de línea", que ha encontrado en la string, es decir, aquéllo que viene precedido por el operador \n de las strings, incluidos éstos en los elementos de la lista. Más bien, este método desempeña una función informativa antes que mecánica o funcional.
 |
Con la invocación de este método podremos comprobar si la cadena comienza ("STARTSWITH", "empieza con...") con un "PREFIX", "prefijo" concreto, en cuyo caso nos devuelve True o, en caso de que no fuera así, False. Es posible delimitar la búsqueda proporcionando un índice de inicio y un índice final.
 |
30) STR.STRIP(CHARS):
Este método nos devuelve la cadena original ("STRIP", "franja", "cinta") pero con los caracteres que les pasemos como argumentos eliminados de la misma, a condición de que éstos sean caracteres de inicio y/o caracteres finales.
 |
31) STR.SWAPCASE():
Con el método str.swapcase() obtendremos una cadena con las mayúsculas convertidas en minúsculas y las minúsculas convertidas en mayúsculas ("SWAPCASE", "intercambio entre minúsculas y mayúsculas").
 |
32) STR.TITLE():
La llamada a este método procura una string nueva, con los caracteres iniciales de cada substring transformados en mayúsculas. Es un método más o menos complementario a str.lower().
 |
Devuelve una string con todos y cada uno de sus caracteres convertidos en mayúsculas.
 |
34) STR.ZFILL(WIDTH):
Este método, similar a str.just(width, fillchar), antepone tantos 0 ("z" es la abreviatura de "zero", "cero", en castellano) como el ancho que le pasemos como argumento mediante un entero, un int. No permite anteponer ningún otro carácter salvo el mencionado. Puede resultar útil para rellenar espacio a la izquierda de un dígito dado como string.
 |
 |
| ANTIGUA BOMBA DE EXTRACCIÓN DE AGUA EN EL MUNICIPIO DE VILAFLOR, CENTRO SUR DE TENERIFE |

Por fin podemos dar por terminado el extensísimo capítulo dedicado a los métodos de las strings. Quizás hubiera sido mejor dividir el tema en dos capítulos, o tres. Sin embargo, optamos por mantener la modularidad de los capítulos en aras de conseguir una mayor coherencia de contenidos.
Quedan aún dos métodos más de las strings para poner el colofón a este capítulo. Sin embargo, por sus características, por sus relativa complejidad, preferimos exponerlos en una entrada del tipo 2.
T2. LOS MÉTODOS STR.MAKETRANS() Y STR.TRANSLATE( ), DOS AMIGOS MUY BIEN AVENIDOS.
Y como no puede ser menos, los ejercicios de rigor. Echémosle imaginación porque alguno de los propuestos lleva su miga. Venga.


T4. BLOQUE DE EJERCICIOS 2. SOLUCIONES.
 |
| PICA DE IMOQUE, ALTOS DE ARONA, CON UNA ANTIGUA ERA PARA LA TRILLA DE GRANO AL PIE. SUROESTE DE TENERIFE. |
excelente material para los que empezamos en la programación, buena didactica
ResponderEliminarMuchísimas gracias, ROQUE ALBERTO. Ánimo con su aprendizaje. Saludos.
ResponderEliminarHola Gauber, muy buena informacion, y me ayudo con un problema para la conversion de minusculas a mayusculas.. lo que ocurre es que estoy resolviendo uno en el que me pide: **Cuando encuentres una línea que comience con “X-DSPAM-Confidence:” ponla
Eliminaraparte para extraer el número decimal de la línea.
utilice el metodo: startswith() para encontrar las lineas que comiencen con esa cadena, pero me quedo parado al tratar de extraer los decimales, la verdad es que no tengo idea de como hacer eso, se me ocurrio separar en una variable el metodo que utilice de startswith.
mi codigo quedo algo asi:
archivos = input("ingresa el nombre de tu archiv: ")
apertura = open(archivos, "r")
for linea in apertura:
linea = linea.rstrip()
if linea.startswith('X-DSPAM-Confidence:'):
print(linea)
pero es en esa parte de separar los decimales que me he quedado estancado, me podrias aconsejar sobre que leer o por donde va la resolucion, para poder hallarla? no pido que me resuelvas pero si que mes des pistas, que me he quedado toda la noche intentandolo y no he podido, Gracias por tu ayuda.
Hola, Diego Bejar. Muchísimas gracias por la confianza que has depositado en este blog. Una gran alegría haberte servido de ayuda con alguna cuestión. Con respecto a tu consulta (no suelo responder a preguntas sobre código porque, como ya advertí en la introducción, ésa no es la función del blog), como puede tener interés para otras persona, he elaborado un pequeño script que espero que te pueda servir de ayuda. Lo encontrarás en la página PEQUEÑOS CÓDIGOS ÚTILES, en este mismo blog, casi al final. Por el momento es el último apartado que he titulado 'EXTRACCIÓN DE DATOS CONCRETOS DE UN FICHERO'. Ojalá haya podido despejarte las dudas que pudieras tener. Saludos.
EliminarCordial saludo desde Colombia. Muchas gracias por la información me ha gustado cada párrafo explicativo y voy bien con mi aprendizaje. Muchas gracias!
ResponderEliminarBienvenido de nuevo a este blog, Sr. Bayron Perea. Un placer saludarle y conocer de su comentario que le estamos resultando útiles y provechosos. Feliz aprendizaje. Gracias a Ud y saludos al pueblo hermano de Colombia.
ResponderEliminar