 |
| COMIENZA EL DÍA SOBRE LA CIUDAD DE SAN CRISTÓBAL DE LA LAGUNA, LA SEGUNDA CIUDAD EN IMPORTANCIA DE LA ISLA TRAS SU CAPITAL, SANTA CRUZ DE TENERIFE, ISLA DE TENERIFE, ARCHIPIÉLAGO DE LAS CANARIAS, ESPAÑA. Pongámonos en la siguiente situación: ha llegado el invierno y conviene hacer limpia del fondo de armario. Guardamos la ropa de verano y casi toda la de entretiempos y sacamos las que nos proporciona más abrigo. Revisamos su estado y comprobamos que nos vendría bien comprar un gabán nuevo.  Dicho y hecho. Nos vamos a la tienda (o "de tiendas") de ropa más cercana o de nuestro gusto y nos dedicamos a mirar gabanes, abrigos, sobretodos, trincheras, gabardinas,... Ahora bien. Si encontramos alguna que nos llame la atención...¿lo compraríamos tal cual, sin habérnoslo probado antes? Poder, podríamos. ¡Claro que podríamos! Pero nos arriesgamos, y sería nuestra responsabilidad, a encontrarnos con una serie de problemas o, cuando menos, de imprevistos: no es de nuestra talla, no parece que tenga buena calidad, ¡Uy, un roto!, ¡Uy, un descosido!, ¡Pero si no tiene bolsillo interior!, ¿Y esta mancha que no vi en la tienda?, ¿Por qué no cierra bien la cremallera?, ¡Santo Dios, esta manga es más larga que la otra!,... etc. Para evitar o paliar al menos hasta lo razonable estas situaciones, están los probadores, esas cabinas minúsculas e incómodas con grandes espejos sospechosamente deformantes diseñadas para que nos pasemos el menos tiempo posible en ellas. Aquí es donde uno prueba su compra potencial: la observa, la estudia y se la pone encima para ver qué tal y donde decide, finalmente, según el resultado de su propio juicio, si la adquiere o no. De aquí la importancia de las pruebas. Todos los seres vivos, y los humanos por nuestra extraordinaria complejidad como especie los que más, nos pasamos todo el tiempo, siendo más o menos conscientes de ello, haciendo pruebas: nos miramos al espejo para evaluar nuestra apariencia física, saboreamos los alimentos antes de ingerirlos, tanteamos qué momento del día es el mejor para salir a dar un paseo o cumplir con nuestras obligaciones, ensayamos posturas en la cama para dormir mejor, catamos el vino, probamos el agua que bebemos no tenga un sabor raro, incluso hay quienes valoran si este blog para conocer un poco mejor Python vale la pena seguirlo o no.  Y, cómo no, la PRUEBA, así, en mayúsculas, es un recurso inalienable, necesario e intrínseco al acto de programar, cualquiera que sea el lenguaje elegido para tal fin y cualquiera que sea el nivel, tanto del programa como del programador. Es la prueba lo que determina si nuestro trabajo ha valido la pena o no y su calidad como producto final. Aunque nos parezca mentira... casi que sí. Que sí. Que hemos codificado un script o puede, incluso, que un programa más complejo. Y hemos pulsado Intro para ver qué tal funciona, si funciona bien, si funciona mal o si, simplemente, no funciona ni por casualidad. Y cada vez que hemos efectuado el ritual de introducir (si lo hemos establecido así, claro está) datos a nuestro script/programa y/o añadir tantas o cuántas líneas de código y pulsar Intro, con esa carita ansiosa que se nos pone y el corazón encogido en un puño, efectuamos una PRUEBA. Pues bien, a esta primera prueba MANUAL, de andar por casa, vamos, y que efectuamos nosotros mismos, de manera "artesanal" por así decirlo, constituye el nivel más BÁSICO y se le da el nombre de prueba exploratoria.  ¿Por qué exploratoria? Porque lo que realmente hacemos es explorar todo nuestro código, a veces al final del mismo si no es muy largo, pero mayormente cada pedazo del mismo, con cada bifurcación, con cada método, etc. a la caza y captura del temido error, localizarlo, analizarlo, corregirlo y vuelta a empezar, repitiendo el proceso hasta que todo funcione correctamente y la ejecución del código arroje los resultados esperados. El planteamiento ideal es construir un PLAN DE EXPLORACIÓN, esto es, planificar de antemano cómo vamos a probar nuestro código de la manera más completa y eficaz: para esto, con papel y boli, anotamos todas las características y elementos que queremos evaluar, todos los tipos de datos (valores) que puede ingresar externamente (inputs) nuestro código, y de acuerdo a estos dos factores y al manejo que hace nuestro script de los datos a nivel interno (si los modifica o no, si bifurca un determinado tipo de dato en una línea de ejecución u otra, los iteradores, etc.), establecer qué resultado esperamos obtener. Por supuesto, intrínsecamente ligado al acto de prueba, tenemos a nuestra disposición las herramientas que Python nos proporciona para el manejo de errores (v. TRATAMIENTO DE EXCEPCIONES), y los "checkpoints", los puntos de control, por así decirlo, que nosotros mismos insertamos en nuestro código para controlar el tipo de datos que ingresamos a través de un input, como por ejemplo, una regex, una expresión regular, (v. EXPRESIONES REGULARES 1 y EXPRESIONES REGULARES 2) que determine que el tipo de dato sea una cadena de texto de tanto tamaño y que no contenga números, por ejemplo; las propias funciones conversoras como int() que garantiza la conversión a entero de una entrada que, recordemos, siempre, por defecto, lo hace como strings; o el manejo de condicionales para tratar de una manera u otra un valor según sea su tipo de dato.  Muchas veces, aunque parezca mentira, este tipo de actuaciones: prueba manual (exploratoria) y verificación de checkpoints, si se realizan bien, concienzudamente, resultan suficientes, aunque más de uno, dos y hasta tres puristas de la cosa grite "¡Herejía! ¡Herejía!", para asegurarnos que nuestro código funcione correctamente.  AÚN LADRO MÁS: LA PROPIA NATURALEZA MODULAR DE LA PROGRAMACIÓN ORIENTADA A OBJETOS DONDE TODO SE SUBDIVIDE EN PEQUEÑOS TROZOS QUE, LUEGO, TERMINAN POR ENSAMBLÁRSE DE MANERA ORDENADA PARA OBTENER UN PRODUCTO MÁS COMPLEJO. AYUDA EN ESTE SENTIDO SI VAMOS PROBANDO MANUALMENTE (LO QUE ENTENDEMOS POR "EXPLORACIÓN") CADA TROZO Y, PARTE A PARTE VAMOS VERIFICANDO QUE NUESTRO CÓDIGO FUNCIONA CORRECTAMENTE Y SE DEVUELVEN LOS RESULTADOS QUE ESPERAMOS OBTENER, EN EL MOMENTO DE "ENSAMBLAR" MÓDULOS, POR ASÍ DECIRLO, PARA OBTENER ESE PRODUCTO MÁS COMPLEJO (UNA CLASE, POR EJEMPLO, COMPUESTA POR DISTINTOS MÉTODOS) AL QUE ALUDÍAMOS MÁS ARRIBA, LAS POSIBILIDADES DE QUE TODO EL CONJUNTO FUNCIONE CORRECTAMENTE AUMENTAN SIGNIFICATIVAMENTE. Con lo antedicho, lo que queremos subrayar es que no es necesario obsesionarse con pruebas profundas, con el uso exhaustivo de código de verificación, y cosas así. Realmente, nos sorprendería saber cuántos buenos y relativamente complejos programas y aplicaciones que deambulan por ahí, están a nuestra entera disposición con sólo haber pasado pruebas manuales, abundantes y muy rigurosas, sí, pero hasta ahí. Pero llegados a este punto hay que poner los puntos sobre las íes. Si tenemos un problema con un cierto nivel de complejidad y sabemos que, tarde o temprano, tendremos que añadir, eliminar y/o modificar código para mantenerlo y/o optimizarlo, qué duda cabe, lo mejor es AUTOMATIZAR el proceso de prueba. ¿A qué nos referimos con automatizar pruebas? Anteriormente habíamos dicho que una prueba manual como Dios manda exige una cierta planificación, elaborar un proceso que tenga en cuenta todas las eventualidades posibles que puedan afectar a la ejecución de nuestro código, haciéndolo nosotros mismos con el sudor de nuestra frente. Pues bien, se trata de que el mismo proceso, en vez de hacerlo nosotros, lo haga el propio Python a través de un script que codifique ese mismo proceso y lo ejecute en nuestro lugar. Eso sí, será capaz de identificar los errores pero el corregirlos corre de nuestra cuenta. Esta última frase es clave. Insistimos, Python nos dirá si ha encontrado un error, qué tipo de error y hasta dónde lo ha encontrado. Pero encontrar y determinar la causa, el motivo, el por qué de ese error... ¡Ah, amigo! Eso corre de nuestra cuenta. Ciertamente, Python nos provee de una buena librería para afrontar esta contingencia, desde elementos de checkpoint como como los que ya hemos mencionado, condicionales e iteradores, y keywords como assert: assert "123".isdigit() == True, "Debe ser verdadero" assert pow(2,3) == 8, "Debe ser 8" Estos checkpoint, condicionales, iteradores, etc. constituyen, por así decirlo, nuestra primera línea de prueba, hasta los módulos doctest, unittest y otros, que se integra como un completo arsenal antierrores. Tal y como sostiene D. Anthony Shaw (tonybaloney.github.io) en su excelente artículo Introducción a las pruebas unitarias, del 22 de octubre del 2018 en el blog realpython, lo mejor de lo mejor en cuanto a sitios web de referencia para aprender a programar en Python, existen dos tipos de pruebas:
Si partimos de la base de que la prueba unitaria es algo así como la "unidad básica" de prueba o testeo en un programa/aplicación, empecemos, pues, por ella para ir poco a poco abordando aspectos un poquito más complejos más adelante.  PRUEBAS UNITARIAS: MÓDULO unittest El módulo unittest de la librería estándar (stdlib) de Python es el encargado de llevar a cabo las pruebas unitarias si no queremos acudir a librerías externas. Sele conoce también como PyUnit, donde el sufijo Unit hace referencia a un conjunto de parámetros construidos ex profeso para ejecutar pruebas unitarias en diferentes lenguajes de programación, y que se conocen como XUnit, donde X es el prefijo que apunta al lenguaje de programación en concreto. En nuestro caso, Py, el prefijo, señala a Python, como fácilmente podemos deducir. Vamos, digo yo.  ESTO SE RELACIONA CON EL PROCESO DE Unit Testing, QUE ES UNIVERSAL PARA TODOS LOS LENGUAJES DE PROGRAMACIÓN. SU RECURSO ES PARALELO, O CUANDO MENOS, SUELE SERLO, AL MODELIZADO DE UNA CLASE, DE CARA A PROBAR SOBRE LA MARCHA LA IDONEIDAD DE SUS MÉTODOS ANTES DE PASAR A MODELIZARSE LA CLASE SIGUIENTE; O BIEN SI ESTA CLASE (Y, EN CONSECUENCIA, EL MÓDULO QUE LA CONTIENE) EXPERIMENTA ALGÚN TIPO DE MODIFICACIÓN. SIEMPRE SERÁ CONVENIENTE MODELIZAR UNA CLASE ESPECÍFICA DE PRUEBA (Unit Testing). DENTRO DEL PROPIO MÓDULO, AL MARGEN O A CONTINUACIÓN DE LA CLASE O CLASES QUE CONFIGURAN EL PROPIO MÓDULO PARA QUE PUEDAN TRABAJAR INDEPENDIENTEMENTE. DENTRO DEL CONJUNTO DE ESTILOS DE PYTHON SE CONSIDERA UNA BUENA PRÁCTICA INCLUIR UNA CLASE DE PRUEBA POR CADA MÓDULO DEL QUE DISPONGA NUESTRO PROYECTO. TODO ELLO GENERA UNA SUERTE DE ENTORNO O MARCO DE PRUEBAS, Y DE AHÍ QUE AL MÓDULO Unittest SE LE DENOMINE TAMBIÉN marco de pruebas. Este módulo Unittest cuenta con una serie de herramientas que nos permitirán probar nuestro programa o aplicación dentro del mismo código. En este punto nos interesa saber qué es un caso de prueba: un caso de prueba es una acción única de prueba que actúa sobre el código que queremos probar para comprobar si su ejecución devuelve o no la respuesta que esperamos. Trasladado este concepto al ejemplo que hemos mostrado tenemos:  Si queremos ser puristas y escudriñar nuestro código a la busca y captura del más leve gazapo binario podemos adherirnos a la versión más exhaustiva de la idea, y considerar todas y cada una de las situaciones posibles de prueba/testeo que se nos ocurran sobre el trozo de código que queremos evaluar. Sobre el ejemplo anterior podemos construir un nuevo caso de prueba:  Si al caso anterior sumamos los casos de prueba 1. y 2. tenemos un conjunto de casos de prueba. Pues bien, un conjunto de casos de prueba tanto para aplicar sobre un mismo trozo de código (una función, en la mayoría de los casos, o un método si estamos dentro de una clase) como en varios de ellos es lo que se denomina banco de pruebas.  EXCEPCIONES ASERTIVAS Las excepciones asertivas (assert) son constructos sintácticas de Python que se configuran como booleanos puros, es decir, que sólo devuelven True o False como resultado de la evaluación de una condición implícita. A continuación mostramos una tabla con los métodos de tipo assert más usuales dentro de unittest.  Más adelante veremos unos cuantos ejemplos de uso.  Vamos a escribir un código sencillísimo basado en una función y lo probamos:  En el ejemplo construimos una función que llamamos test_areatriangulo y que devuelve el área de un triángulo pasando como parámetros la base, b, y la altura, a, según nos indica la sentencia return, el pie de la función. Sin embargo, en el cuerpo de la propia función hemos incluido dos aserciones (assert), lo que nos dice que hemos incluido las pruebas dentro de la propia función, sin necesidad de efectuar llamadas externas. La primera aserción evalúa que los datos que pasemos como argumentos de la función sean números, para poder así efectuar los cálculos aritméticos; mientras que la segunda aserción evalúa que el resultado de calcular el valor del área sea mayor o menor que 1, lanzando una excepción de tipo AssertionError en el caso de que fuera igual o inferior a 1. En 1., la ejecución de la función devuelve un resultado sin más, ya que los datos que se pasan son del tipo correcto para efectuar un cálculo aritmético y el resultado "parece ser" que va a ser superior a 1. En 2., la ejecución de la función devuelve una excepción de tipo AssertionError dado que el valor del área es inferior a 1. Sin embargo, en 3., si bien es cierto que se lanza una excepción ésta es de error de tipo (TypeError) ya que no es posible operar aritméticamente entre un tipo de dato numérico y una cadena, pero no es una AssertionError a pesar de que así lo hemos indicado. ¿Por qué el intérprete de Python ignora nuestra prueba de aserción? Fundamentalmente por una cuestión de jerarquías: las excepciones predefinidas en Python como TypeError, ValueError, IndexError, ZeroDivisionError, etc... prevalecen sobre las de tipo asertivo, ya que nosotros mismos establecemos qué tipo de error debe evaluarse: como la excepción predefinida TypeError es igual a nuestra excepción de "elaboración propia" y la primera es predefinida en Python, es ésta la que lanza per sé ignorándose la segunda. Con esto, lo que queremos insinuar es que nuestras declaraciones de tipo assert debe apuntar a evaluaciones que no impliquen repetir una posible excepción predefinida de Python, como en el caso 3., ya que no tiene sentido, sino en incidir sobre otros aspectos susceptibles de ser evaluados pero que no "suplanten" por sí mismas a excepciones predefinidas, como en 2.  Hasta ahora hemos empleado las aserciones de manera directa a través de la inclusión en el código de la sentencia assert que, digámoslo así, nos ofrece el modo más básico de prueba no exploratorio o manual (recordemos, el que efectuamos nosotros mismos sobre el código). Ahora, sin embargo, por decirlo así, assert "sube de nivel" y se integra dentro del módulo unittest, en la clase TestCase que, si lo traducimos al castellano, obtenemos, mire Ud. por dónde, "Caso de Prueba", adquiriendo un grado mayor de automatismo y versatilidad. Para conseguirlo, debemos efectuar una importación genérica de la librería estándar unittest, modelizar una clase dedicada de manera específica a efectuar pruebas y, en su zona de herencias, llamar a la clase TestCase, que será así su clase padre o superclase, ligada al módulo por el método del punto, el dott method. Sería algo así como:    ¿Recordamos lo que aprendimos en el capítulo dedicado a la herencia (v. HERENCIA)? Aquí aprendimos que las herencias pueden ser un problema y que las herencias múltiples, sobre todo, las carga el diablo. Por este motivo conviene modelizar una clase específica, ad hoc, dedicada en exclusiva a las pruebas, y no incorporar la clase padre TestCase dentro de la zona de herencias de otra clase cualquiera de nuestro código, y efectuar pruebas dentro del ámbito de la propia clase. ¡Y menos aún si ya hereda o extiende de otra clase padre! Al margen de lo dicho, siempre es conveniente SEPARAR las clases que construyen y ejecutan nuestro código de la clase de prueba. A partir de esta estructura ya podemos empezar a llamar a los diferentes métodos, como los que mostramos en la tabla, de los que dispone la clase TestCase. Vamos a centrarnos en un ejemplo que tomamos directamente de la documentación de Python.  En el ejemplo se comienza, cómo no, importando el módulo unittest, e inmediatamente después, se modeliza la clase TestStringMethods que desde su zona de herencias hereda o extiende de la superclase o clase padre TestCase, del módulo antes citado unittest mediante el método o la sintaxis del punto. El primero de los tres métodos, test_upper(), en su ámbito o cuerpo de la función y siempre a través de la autorreferencia self y, de nuevo, la sintaxis del punto, llama o invoca al método assertEqual de la clase padre TestCase. En su zona de parámetros, lleva una expresión como primer argumento 'foo'.upper(), esto es, una string o cadena, 'foo', sobre la que se aplica el método upper() que convierte a cada elemento de la cadena en mayúscula. Como segundo argumento pasamos aquéllo que esperamos obtener: 'FOO'. Lo que hace el método assertEqual() es COMPARAR (➡ Equal) que el resultado de ejecutar la expresión (debería devolver precisamente 'FOO') y el resultado que hemos propuesto en el segundo argumento, 'FOO', sean IGUALES, que no IDÉNTICOS, como vemos a continuación con una versión del primer método de la clase TestStringMethods, donde pedimos que Python nos muestre los respectivos id, tanto de la expresión como del presunto resultado, s1 y s2, respectivamente.  El segundo método de prueba en nuestro caso, test_isupper(), incorpora dos evaluaciones booleanas (aquéllas, recordemos, que sólo devuelven como resultado True o False, y que identificamos rápidamente con cualquier método predefinido o nativo en Python que comience con el prefijo -is (¿Es...?)). El primero, assertTrue(), que lleva como único argumento una expresión: el método booleano isupper() sobre una cadena, 'FOO', del que podemos pronosticar sin temor a equivocarnos que devendrá verdadero. Justo debajo, tenemos el segundo método, assertFalse(), y que también lleva como único argumento, lleva en su zona de parámetros una expresión similar a su predecesora pero aplicada sobre la cadena 'Foo', de la que igualmente podemos pronosticar que devendrá falso, que es lo que sostiene assertFalse(), porque sólo el primer carácter de los tres que contiene la cadena es mayúsculo. Finalmente, tenemos un tercer método, test_split(). En este caso, tenemos una string almacenada en una variable que llamamos s, y que dispone de once caracteres literales donde uno de ellos, el que lleva un valor de índice 5, es un espacio en blanco, whitespace, y que el método split() de las strings separa (to split = "escindir", "dividir") una string en una o más substrings dentro de una lista, cada una de éstas separadas por comas, en función del parámetro que le pasemos. Si no pasamos ninguno, como es el caso, el parámetro, por defecto, será un espacio en blanco. Por este motivo, el resultado de la ejecución del método assertEqual() será positivo, pues coinciden el resultado de ejecutar la expresión y la propuesta de resultado a obtener: ['hello', 'world']. Contamos con un código añadido para chequear qué sucede cuando el separador (el parámetro del método split()) no es una string, una cadena. Este código, a través de la palabra clave, keyword, with (v. T2. WITH: EN BUENA COMPAÑÍA). Esta declaración genera un entorno propio, scope, muy útil para trabajar en manejo de excepciones o para automatizar procesos, como cerrar archivos una vez los hayamos leído o actualizado (flujo de archivos, se llama la cosa). En este punto llamamos al método assertRaises() de la clase TestCase, que se encarga ella solita de comprobar las posibles excepciones que puedan darse en la ejecución de un código (sí, también, por probar, podemos probar hasta los errores) bajo la sintaxis: with self.assertRaises(excepción): código (hacer algo a través de una función) En este caso pasamos como parámetro la excepción TypeError, error de tipo de dato, que en este caso se da si el parámetro que pasamos al método split() no es una string, None o dejamos vacía la zona de parámetros.  ¿Qué es lo que se ha hecho en este código? Pues correr (o "ejecutar", en la jerga informática, to run) una serie de pruebas (tests) dentro de una clase, TestStringMethods, que hemos modelizado justamente para eso: probar nuestro código, ergo, hemos efectuado un RUNTEST. ¿Y cómo podemos traducir un runtest en castellano? Pues como "Corredor de pruebas". ¡Vaya por Dios! ¿Y qué es un "Corredor de pruebas"? Pues un código que automatiza la ejecución (to run) de pruebas (tests) y, fruto de ello, devuelve un resultado. Esto es lo que es, exactamente, unittest: un sofisticado "Corredor de pruebas" que Python pone a nuestra disposición directamente a través de su librería estándar. No es ni mucho menos el único corredor de pruebas al que podemos acceder para probar nuestros códigos. Existen algunos más, siendo el más utilizado PyTest, que es una librería externa, de terceros, que podemos descargarnos fácilmente a través de pip install, un programa predeterminado de instalación de contenidos en Python. CARACTERÍSTICAS ESENCIALES DEL MÓDULO UNITTEST
 FIJÉMONOS QUE TODOS LOS NOMBRES DE LOS MÉTODOS/CASOS DE PRUEBA COMIENZAN CON EL PREFIJO TEST_ AL QUE AÑADIMOS UN NOMBRE. ESTO ES ASÍ POR CONVENCIÓN ENTRE PROGRAMADORES Y SE CONSIDERA UNA BUENA PRÁCTICA NOMINAR ASÍ A NUESTROS CASOS DE PRUEBA. TAMBIÉN LO ES COMENZAR NOMBRANDO A LA CLASE QUE EJERCE COMO CONTENEDOR DE CASOS DE PRUEBA CON LA PARTÍCULA TEST. ES MÁS, ESTA CONVENCIÓN A DEVENIDO EN NORMA, POR LO QUE SI NO PREFIJAMOS NUESTROS MÉTODOS/CASOS CON TEST_ NO FUNCIONARÁN.    MÉTODO assertAlmostEqual() El método assertAlmostEqual() es un método pensado para el cálculo fino, aquél que demanda un exquisito grado de precisión. Un método apropiado para el cálculo científico/matemático donde un sólo decimal determina si algo es de una manera o de otra, si conviene aplicar algo o no, si debemos hacer esto o lo otro, si es un acierto o un error. Cuando llamamos al método y colocamos el paréntesis de apertura, como ya estamos acostumbrados cuando de una función o método se trata, Python muestra un cuadro de texto informativo sobre los defectos y virtudes del método en cuestión. Veamos: assertAlmostEqual(first, second, places=7, msg=None, delta=None) Como vemos, el método cuenta con cinco parámetros de los cuales los dos primeros, first (primero) y second (segundo), son obligatorios mientras que los otros tres son opcionales. A continuación, Python deleita nuestra mente con un texto explicativo que traducido al castellano viene a decir, poco más o menos, lo siguiente: Falla (fail) si los dos objetos (se refiere a ambos objetos obligatorios, a saber, first y second) son distintos, disímiles entre sí, según lo determinado por su diferencia (en decimales, y de aquí el rigor y la precisión que exigimos en el cálculo) redondeada (aplica per se la función integrada round()) al número que proporcionamos como espacios (places) decimales (como vemos, por defecto, si no cambiamos nada, el número de espacios para decimales será siete, places=7) y comparándolo a cero. También es posible que la comparación entre ambos objetos, first y second, fuera mayor que el número que le asignamos al parámetro opcional delta que, según la documentación, la diferencia (resta) entre el primer (first) y el segundo (second) objetos debe ser menor o igual al valor de delta. Los dos últimos parámetros de assertAlmostEqual() son msg=None, donde msg es un acrónimo de message, en referencia a un mensaje de texto que podemos introducir, obviamente como string o cadena de texto, y que se mostrará en el caso de que la prueba devenga errónea (fail), y delta, que inicialmente tiene la keyword None como valor preasignado.  Resumiendo:
 Es importante señalar que a la hora de pasar parámetros debemos elegir entre pasar places o delta, pero no podemos pasar los dos ya que, como veremos en el ejemplo, TestCase arrojará un error de tipo de dato (TypeError) advirtiéndonos de que debemos especificar places o delta pero no ambos a la vez. Conviene también reseñar que si bien, cuando usamos places en lugar de delta podemos introducir el parámetro msg, mensaje, si en lugar de places escogemos delta, por lo menos en nuestro caso, se genera un error. En consecuencia, si queremos mostrar un mensaje cuando obtenemos un fallo debemos recurrir a places; si no queremos mostrar mensaje alguno podemos recurrir indistintamente a places o delta. Veamos un ejemplo de uso:  En este ejemplo, nuestro corredor de pruebas contiene 7 casos de prueba. Muy importante, para que pueda provocarse el runtest, esto es, para que el corredor o marco de pruebas corra, los nombres de cada caso de prueba deben comenzar con el prefijo test_ más el nombre que queramos. Si no lo hacemos así, el corredor de pruebas nos ignorará absolutamente. A continuación, ejecutamos la prueba:  Lo primero que nos muestra, arriba del todo, es lo siguiente: EFFFFF Esto quiere decir que ha encontrado un error y cinco fallos (failures), lo que coincide exactamente con la información que se muestra al final del todo: FAILED (failures=5, errors=1). Recordemos que una prueba superada no recibe notificación alguna, salvo el que lo fueran todas las de un mismo corredor de pruebas, lo que arrojaría una evaluación OK. Esto es así porque TestCase toma el corredor de pruebas como un todo, tanto si tiene un caso de prueba como si tiene 7 como en nuestro ejemplo, como si tiene diez, cien o mil. El caso de prueba test_tensionsistolica1 es el único que ha devenido correcto (tengamos en cuenta que los casos de prueba superados no se anuncian mientras dentro del mismo marco de pruebas donde se encuentre existan uno o más casos de prueba con error o falla. Sólo si todos los casos de prueba de un marco de pruebas fuesen superados, que todos devolvieran True, vamos, se mostraría el resultado OK). Si nos fijamos, observamos que ambos valores, test_10_09_2020 y test_10_10_2020 son decimales (float) con tres espacios decimales. En el tercer parámetro señalamos con el parámetro places igualado a 2 que ése es el margen de coincidencias que hemos elegido y que assertAlmostEqual() debe evaluar. Efectivamente, en ambos valores numéricos, los dos primeros espacios decimales, coinciden: 45, mientras que el tercero es el que varía: 2 en el primer caso y 5 en el segundo. Como la condición se cumple, el caso de prueba test_tensionsistolica1 supera la prueba. Tras la información de la evaluación, EFFFFF, nos informa sobre el caso de ERROR. Éste ha ocurrido en el caso de prueba test_tensionsistolica2, en 2.. Y esto se produce, no porque la evaluación del caso de prueba halla fallado (fijémonos que en el "parte" informativo de la excepción no se muestra una AssertionError) sino porque hemos incurrido en un error de sintaxis en el momento de construir el caso de prueba, como bien nos advierte la excepción en la línea final: hemos incurrido en un error de tipo de dato (TypeError) porque, como nos informa justo a continuación, hemos introducido en nuestro código valores propios para los parámetros places y delta (sólo podemos especificar o places o delta, pero no ambos). Por esa razón tenemos un E como primera devolución de nuestro runtest. En el caso 3., test_tensionsistolica3, tenemos una falla, (fail), esto es, una AssertionError. ¿Dónde ha fallado? Pues en el valor que le hemos dado al parámetro places: le hemos asignado en esta ocasión un valor de 3, cuando en el caso de prueba 1, test_tensionsistolica1, le habíamos asignado un valor de 2 y superó la prueba. Cuando ha leído el tercer valor ha comprobado que son diferentes, 2 en el valor asignado a test_10_09_2020 y 5 en el valor asignado a test_10_10_2020, razón por la cual se produce la falla, salta la excepción y, fijémonos, se muestra el mensaje que teníamos preparado y guardado en el parámetro msg para el supuesto de que la prueba no se superase. En 4. tenemos una nueva falla. Esta vez el asunto obedece al valor tan alto que asignamos al parámetro delta, 14, y podemos ver perfectamente que los valores de test_10_09_2020 y test_10_10_2020 sólo tienen tres decimales cada uno. La valoración en el también es fail, de entrada, porque hemos pasado números enteros, sin decimales, aunque como sabemos, todo número entero es también un decimal un decimal con la asignación .0, es decir, por ejemplo, 14 = 14.0 ó 456 = 456.0. La falla se genera por obviedad. Observemos que en el AssertionError se nos informa de que no encontrara 7 places, espacios decimales. Esto es así por defecto dado que no hemos pasado el parámetro places (tampoco en delta) y, como hemos visto, el método assertAlmostEqual() contiene el parámetro places con un valor preasignado de 7. En el caso de prueba número 6. tenemos también una falla. En esta ocasión si hemos pasado el parámetro places y le hemos asignado el valor 1, es decir, un único decimal a partir del punto. Si comparamos los dos datos, el primer decimal de test_10_09_2020 es 0 mientras que el primer decimal de test_10_10_2020 es 3. Son diferentes, ergo no se supera el caso de prueba. Finalmente, en el caso de prueba número 7, volvemos a tener una falla, para variar. Hemos pasado a places un valor de 2 para que compare los dos primeros decimales tras el punto, de manera análoga a como procedimos en el caso de prueba 1. Para ambos datos a comparar, test_10_09_2020 por un lado y test_10_09_2020 por otro, estos dos número decimales son iguales: .90 en ambos casos. Entonces, ¿por qué se produce el fallo? Porque lo que no coincide es la parte entera de ambas cifras: 14 para la primera variable y 13 para la segunda. Notemos, además, que en el AssertionError se muestra el mensaje que pasamos al parámetro msg.  FACHADA PRINCIPAL DE LA CATEDRAL DE LA LAGUNA, EN UN SENCILLO Y AUSTERO ESTILO NEOCLÁSICO CANARIO. PARÁMETRO delta El parámetro delta, en el método assertAlmostEqual(), aporta un grado más de precisión aunque, como ya hemos explicado, no es posible pasar a la vez los parámetros places y delta: debemos, necesariamente, optar por uno u otro. El valor de delta determina la diferencia máxima que debe haber entre los dos valores que pasemos como parámetros obligatorios para efectuar la comparación. Si la diferencia entre ambos es igual o menor al valor que asignamos a delta, el caso de prueba es superado (👏); si es mayor, el caso de prueba no es superado (👎), la evaluación deviene False y el método devuelve fail. Recordemos además que su valor predeterminado es None.  Vamos a comprobar esto con un ejemplo:  La ejecución del corredor de pruebas arroja dos fallas, failures, habiendo corrido el test en 0.038 segundos (en el equipo de un servidor). Encuentra un primer fallo en el caso de prueba test_tensionsistolica1, en 1., debido a que la diferencia entre los valores de test_10_09_2020 y test_10_10_2020 es mayor que 2, que es el valor que le hemos asignado a delta: 79 - 40 = 30. Encuentra un fallo también en nuestro tercer caso de prueba, 3., en tanto que, de nuevo, la diferencia entre los decimales del primer y segundo valor, 60, (79 - 19 = 60) es superior a 5, el valor que asignamos a delta. Pero nuestro segundo caso de prueba, 2., sí supera la evaluación. Le hemos proporcionado a delta un valor muy bajo buscando un máximo de precisión (podemos pasar a delta valores decimales, no necesariamente valores enteros, como por ejemplo, 0.7, 1.35 ó 0,00001, afinando la precisión del análisis a límites muy exigentes). Y en esta ocasión, como la diferencia entre entre test_10_09_2020, 14.79, y test_10_10_2020, 14.78 es 1 (14.79 - 14.78 = 1) y este valor coincide con el valor que proporcionamos a delta, 1, nuestro caso test_tensionsistolica2 consigue superar la prueba. ¡Olé! Por cierto, como comprobamos en el ejemplo que sigue, el orden de los factores no altera el producto: independientemente de que pasemos un determinado objeto como primero o segundo argumento obligatorio, siempre se establecerá la diferencia en positivo, es decir, por encima de 0, restándose el menor de entre ambos valores al mayor.   setUp() y tearDown() Cuando contamos con muchos casos de prueba (métodos test_*, en su forma sintáctica) conviene "organizar" nuestro código de prueba para que la cosa no se nos vuelva jaquecosa. Y es aquí donde entran en concierto dos conceptos importantes: preparación y limpieza, que toman cuerpo en unittest a través de los módulos setUp() y tearDown() en la clase TestCase respectivamente:
setUp(): Como hemos dicho se trata de un método de TestCase que ejecutará en orden de flujo de lectura cada caso de prueba de manera automatizada, y se invoca en el backend de Python con cada caso de prueba (método) que se encuentre. En el supuesto de que en un momento dado durante la ejecución de setUp() se detectara un error y se lanzara la excepción correspondiente, el módulo unittest, el marco de pruebas, vamos, considera que se ha obtenido un error, detiene el flujo de ejecución para mostrar la excepción, y continúa con el siguiente código de prueba si lo hay. Vemos los siguientes dos ejemplos. En el primero tenemos un marco de pruebas con varios casos de prueba a evaluar donde todas las ejecuciones devienen correctas:  En el segundo introducimos dos casos de prueba, el tercero y el cuarto que, ya de antemano, sabemos que van a dar error:  Corremos la prueba, runtest, con el corredor de pruebas unittest y esto es lo que obtenemos:   En 1., las dos F nos indican, de entrada y a bote pronto, que nuestro código de prueba arroja dos fallos, failures. A continuación, el corredor de pruebas nos informará sobre los dos fallos, fails, que ha identificado en nuestro marco de pruebas. En 2., y siguiendo un orden inverso al flujo de ejecución, esto es, desde el último fallo que encuentra hacia atrás, nos informa de que ha encontrado una falla o error, fail, y nos dice dónde, en qué caso de prueba (test_cuarto), y entre paréntesis, nos indica el marco de prueba (clase) donde se ha ejecutado (TestString) por si contáramos con más marcos de prueba en nuestro corredor de pruebas (u.py), y fuera necesario distinguirlos unos de otros. En 3., muestra la excepción. Aquí nos informa de la línea de código donde está la falla y, justo debajo, el código que ocupa esa línea. Finalmente, muestra el AssertionError correspondiente y que tanto nos saca de quicio, señalando cuál es el error detectado durante el runtest. En 4., y esto sólo ocurre con algunos casos de prueba en base al código que implementen, sugieren la solución correcta: fijémonos que de acuerdo al ejemplo, se muestra primero un signo menos, -, a la izquierda de la string o cadena "león", lo que nos indica que esto es lo que, precisamente, está mal. Justo debajo, se muestra un signo más, +, a la izquierda de la string o cadena "puma", lo que nos apunta que ésta hubiera sido la solución correcta. Mola, ¿verdad? En 5. nos informa de que ha corrido la prueba sobre cuatro casos de prueba y, ya que estamos, el tiempo que ha invertido en hacerlo. El siguiente error, FAIL: test_tercero (__main__.TestString), sigue el mismo patrón que su predecesor. Finalmente, en 6., se nos informa que el marco de prueba ha fallado (FAILED), así como el número de casos de prueba que han arrojado fallos sobre el total (failures=2).   Añadimos un tercer ejemplo:  En 1. cometemos un error, ¡vaya por Dios!, por el que, a estas alturas, deberíamos ser fusilados (eso sí, virtualmente, claro): nuestro dato para ser evaluado es un número entero, pero el caso de prueba, test_primero, está diseñado para aplicarse sobre un tipo de dato string o cadena. Esto no es un error o un fallo a la hora de correr la prueba: es un error ANTERIOR al procesamiento del marco de prueba, que va a impedir que el runtest se ejecute correctamente desde la primera lectura del caso de prueba. Por este motivo, en 2., en lugar de F (fail) del ejemplo anterior, muestra una E (error). En 3. se nos advierte de que se ha encontrado un ERROR (no una falla (fail) durante la ejecución runtest. Se nos informa en qué caso de prueba (test_primero) y, entre paréntesis, en qué marco de prueba (clase) donde se ha intentado ejecutar (__main__.TestString). En 4. se nos lanza la excepción, pero si nos fijamos, ya no se trata de una AssertionError, que es lo de esperar si se produce un fallo en la evaluación de un caso de prueba, sino un TypeError, un tipo de error EXTERNO al corredor de pruebas. Como en toda excepción en Python, se nos proporciona una información sucinta del por qué del error (el argumento (dato) de tipo int no es iterable). Esta excepción viene precedida, en *, por la expresión "if member not in container", que lo que quiere decir es que el dato/argumento que pasamos en el SetUp() no se recoge luego en el contenedor de pruebas (el conjunto de casos de pruebas que conforma nuestro marco de pruebas). En 5. nos informe de que ha corrido el marco de pruebas hasta que ha podido, señalando que hay un único caso de prueba (test), y que ha invertido en ello 0.003 segundos. Finalmente, en 6., y al contrario que en el ejemplo anterior, en lugar de informarnos que la prueba ha fallado (FAILED), por un fallo cometido en la ejecución del caso de prueba, nos dice que la prueba, realmente, no se ha ejecutado porque ha ocurrido un error de base, ajeno a la propia prueba, por lo que en lugar de fallos (failures) nos habla de errores (errors=1). Para finalizar con este pequeño apartado dedicado al método SetUp() mostramos un último ejemplo donde incluimos, dentro del propio método SetUp() sendos inputs de datos por parte de un usuario externo, donde podemos ver cómo el método SetUp() ejecuta cada vez un único caso de prueba: nos pide la entrada completa de datos, ejecuta el primer caso de prueba, todo ok, y con los valores ya pasados esa primera vez, en 1., ya sabe que va a haber un fallo (failure) y vuelve a pedirnos una nueva introducción de datos. Como podemos apreciar, no es la solución más adecuada, desde luego, pero funcionar, funciona. Obviamente, lo ideal sería que la data se ingresara a través de un método aparte, y que luego se transfiera al método SetUp().    TearDown(): Existe un proceso dentro del marco de pruebas que recibe el nombre, en inglés, de test fixture, y que podríamos traducir al castellano como "accesorio" o "dispositivo de pruebas", que crea, genera, construye un contexto donde se implementan las estructuras (internas, proporcionadas por el propio módulo unittest.py sin que nosotros tengamos que hacer nada especial) que necesitamos para realizar, según reza la documentación, un corredor de pruebas con uno o más casos de prueba y la deseable acción de limpieza subsiguiente. La implementación para ejecutar el corredor de pruebas la proporciona el método SetUp(); la limpieza posterior la proporciona el método SetUp().  En resumidas cuentas, el método TearDown() es un método propio de TestCase que nos proporciona cierto margen de definición por nosotros mismos como programadores, por ejemplo, seleccionando el medio de destrucción más adecuado para el elemento (tipo de dato) que queremos destruir (por ejemplo, no es lo mismo destruir una cadena de texto, o una lista, por ejemplo, cosa que podemos hacer con la sentencia del, que destruir un widget de Tkinter, cosa que podemos hacer con el método destroy()), añadiendo mensajes para ser impresos en pantalla, la palabra clave pass, etc., y en el que incluimos una o más funciones predefinidas por Python para eliminar los elementos de los casos de prueba y no acumular basura binaria en la memoria con lo que, de paso, le facilitamos el trabajo al garbaje de Python (v. VARIABLES), y cerramos nuestro contexto como Dios manda. Veamos un ejemplo en el que utilizamos la socorrida sentencia destructora del (v. LA SENTENCIA DEL: FUE BONITO MIENTRAS DURÓ) como solución para destruir, tanto el elemento de prueba como el contexto creado un SetUp():  Como vemos en el resultado, lo primero que se muestra, en 1., son los mensajes de eliminación del elemento de prueba, "self.palabra", tal y como lo pasamos al método SetUp(). Lo sabemos porque hemos pedido impresiones en pantalla utilizando la función print(), porque de no haberlo hecho así, sólo se nos mostraría el triste y solitario punto rojo que se muestra siempre tras ejecutarse el corredor de prueba, hayamos incluido o no un método TearDown(). Para ilustrar el concepto de que el método TearDown() nos permite seleccionar la fórmula de destrucción más adecuada a cada caso, veamos los siguientes ejemplos:  En este caso hemos escogido como elemento de prueba una ventana raíz, root, de la librería gráfica Tkinter que incorpora Python en su biblioteca estándar, y que importamos en el cuerpo/ámbito del método SetUp(). Al ejecutarse el corredor de pruebas llamando al marco de pruebas (la clase TestString()), que hemos modificado del ejemplo anterior, se genera la ventana que podamos ver en 1., el resultado de la evaluación del caso de prueba es OK, pero no se destruye ni el elemento de prueba (self.root) ni el contexto o el entorno de prueba (text fixture) porque al método TearDown(), simplemente, le hemos pasado en 2. la palabra clave pass.  Veamos a continuación qué ocurre cuando pasamos la sentencia del a nuestro método TearDown():  Esta vez hemos pasado la sentencia del en su variante "funcional", con paréntesis, lo que implica llevar argumento, al cuerpo/ámbito del método TearDown() y le hemos pasado como argumento el elemento que queremos destruir: self.root. Vemos que TearDown() se ejecuta, pues imprime texto en pantalla y no se lanza ninguna excepción. Efectivamente, TearDown() ha eliminado el contexto, pero no ha eliminado al elemento de prueba, como vemos en 1., nuestra ventana raíz, abierta de par en par de manera indefinida en la pantalla del ordenador. Podemos concluir, empero, que la sentencia del no es la solución adecuada al caso. Veamos qué sucede cuando en lugar de la sentencia del, recordemos, en su variante "funcional", utilizamos el método destroy(), más competente para el caso: 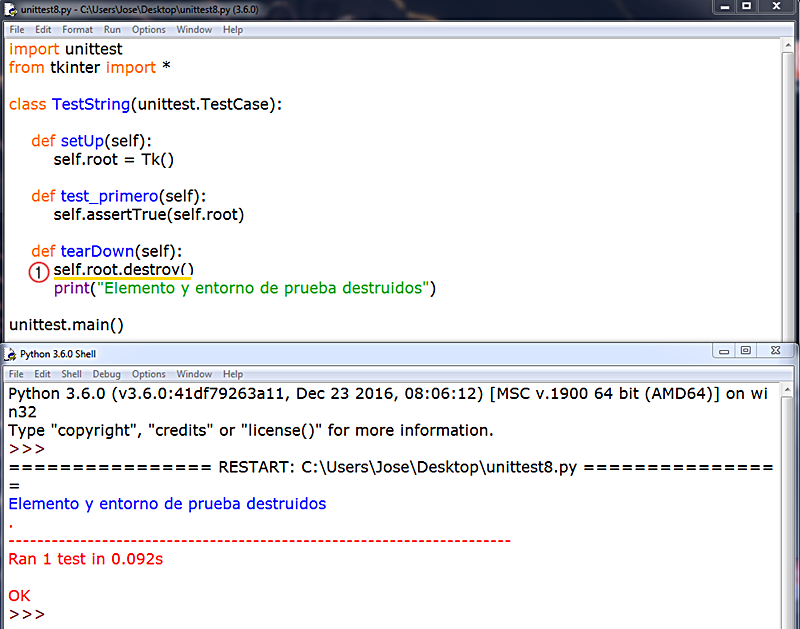 ¡Ah! Esta vez, sí: al usar el método destroy() en lugar de la sentencia del se eliminan ambas cosas: el contexto, el text fixture, y el elemento de prueba, self.root. Un aspecto a tener en cuenta es que el método TearDown() se ejecutará siempre independientemente del resultado de la ejecución del marco de pruebas. Lo vemos a continuación en los dos ejemplos que se muestran debajo:   Concluimos, pues, que para conseguir que el método TearDown() se ejecute correctamente, el resultado de la evaluación del caso de prueba (o de los casos de prueba, en el caso de que haya más de uno) debe ser, necesariamente, OK. Y para que éste se ejecute del modo esperado es necesario, además, elegir el método de destrucción adecuado a cada elemento/tipo de dato en cada caso de prueba. Para finalizar con mm en el ejemplo que sigue mostramos cómo aplicar dentro de un mismo marco de pruebas varios entornos, text fixtures, separados con una envoltura try/except por entorno de pruebas, obteniendo los resultados esperados.   VIVIENDAS ANTIGUAS TÍPICAS DE LAS CALLES DEL CASCO HISTÓRICO DE LA CIUDAD. AL FONDO, EL MACIZO VERDE DE ANAGA. OMISIÓN DE PRUEBAS Y FALLOS ESPERADOS Puede ocurrir que, en ocasiones, dentro de un mismo marco de pruebas, Test Fixture, entendamos que uno o más casos de prueba no deban ejecutarse, o introducir casos de prueba que arrojen fallos, failures, porque, como todo el mundo sabe, las cosas pueden hacerse por activa o por pasiva, o definirse una cosa por lo que es... o por lo que no es, por lo que hace... o por lo que no hace. Y las pruebas se ajustan también a este criterio. Como decíamos, ocurre que a veces podemos desear omitir una prueba, casos de prueba o, hasta incluso, toda una señora clase de pruebas. Esto lo podemos hacer desde el módulo unittest.py de Python usando el decorador (v. DECORATORS) skip(), cuya traducción del inglés al castellano es, mire usted por dónde, "omitir", "saltar por encima de" ➡ pass over. El decorador skip() lleva un único argumento: reason (skip(reason)). Se trata de describir mediante una string o cadena la razón, el motivo, reason, por el que debe omitirse la prueba. Veamos un ejemplo: 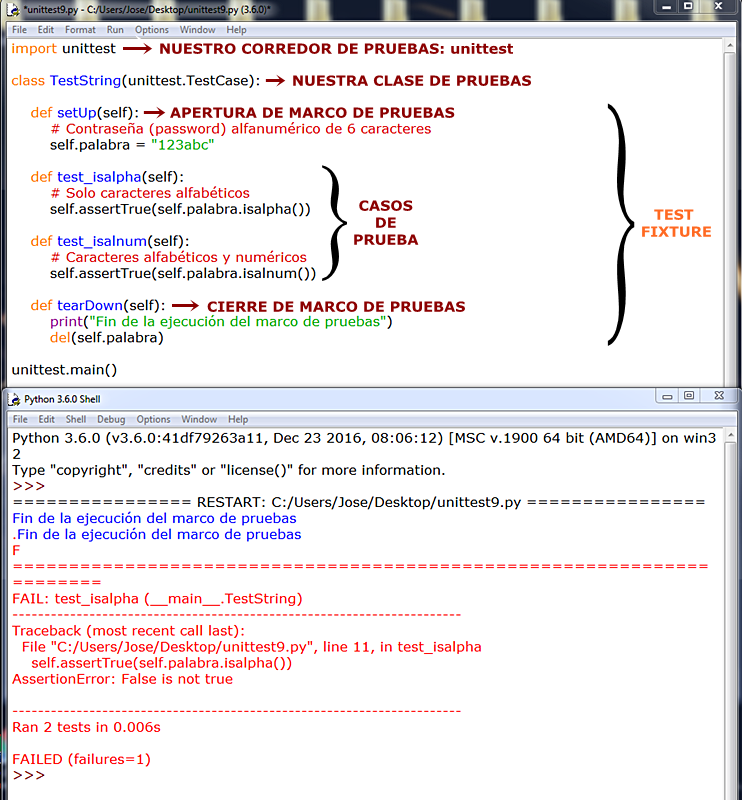 En este ejemplo obtenemos un FAIL para el caso de prueba Test_isalpha, dado que nuestra contraseña, self.palabra, contiene caracteres alfabéticos y numéricos, lo que a su vez consigue que el caso de prueba Test_isalnum sea superado. Imaginemos que queremos que todas las contraseñas, self.palabra, por cuestiones de seguridad, sean alfanuméricas. Podríamos entonces añadir el decorador @unittest.skip(reason) a nuestro Test Fixture y modificar el código del siguiente modo:   Como podemos ver enmarcado en amarillo hemos introducido un decorador @unittest.skip(reason) justo encima del caso de pruebas que queremos omitir, Test_isalpha. Así, cuando toque ejecutar el marco de pruebas, el corredor de pruebas, unittest, cuando alcance al decorador en su flujo de lectura, recordemos, de arriba a abajo y de izquierda a derecha, ignorará el caso de prueba que se ubique justo debajo suyo, y continuará con el flujo de lectura hasta alcanzar el siguiente caso de prueba, Test_isalnum. Como no tiene ningún decorador @unittest.skip(reason) encima, lo ejecutará, y cerrará el marco de pruebas, Test Fixture, con el método TearDown() de limpieza. En 1. se muestra la respuesta .S que nos advierte de que en nuestro marco de pruebas existe una omisión (así se mostrarán tantas .S como omisiones (decoradores @unittest.skip(reason)) hayamos insertado en nuestro marco de pruebas, como .F se mostrarán por cada FAIL que obtuviéramos, o .E por cada ERROR de sintaxis detectado, como podemos corroborar revisando los ejemplos anteriores. En 2. podemos ver la conclusión OK y, justo a continuación, un paréntesis donde se nos informa de cuántos casos de prueba han sido omitidos (skipped). En este caso, uno tan sólo: skipped=1.  Los textos del argumento reason sólo son visibles cuando trabajamos en la consola de comandos. Por eso no se muestran en la resolución del IDLE de Python. Disponemos también de la opción de omitir un determinado caso de prueba en función de que se cumpla o no una condición concreta que pasamos por parámetro. Para conseguir ésto unittest nos provee del decorador @unittest.skipIf(condition, reason), donde el sufijo If apunta claramente a su carácter condicional. Como vemos, en su zona de paréntesis pasamos la condición que queremos imponer como primer argumento, y la razón como segundo, en ambos casos, obligatorio. Veamos un ejemplo:  Aquí hemos introducido, resaltado en amarillo, nuestro decorador @unittest.skipIf(condition, reason), donde la condición a evaluar es la versión de Python que tenemos instalada en nuestro equipo (sys.version), teniendo en cuenta que a través de una slice, rebanada, acotamos la substring que nos proporciona el dato exacto para comparar, [:5]. Si ésta es igual a "3.6.0" se ejecutará el caso de prueba; si no lo es, omitirá el caso de prueba. En 1. podemos ver cómo hemos obtenido el número de la versión de prueba (fijémonos que aquí se justifica el uso de la técnica de slicing de la que hablábamos justo arriba, donde [:5] devuelve 3.6.0.) Como éste coincide con la condición, se omite el caso de prueba y no se ejecuta. Por tanto, en 2., se muestran dos epígrafes .ss, el primero por @unittest.skip(reason) y el segundo por @unittest.skipIf(condition, reason), y en 3. la conclusión OK con las omisiones detectadas: 2.   En este ejemplo, la condición no se cumple, por lo que el decorador @unittest.skipIf(condition, reason) se inhibe y el corredor de pruebas ejecuta el caso de prueba test_versionPython(). En 1. muestra un epígrafe .s por el decorador @unittest.skip(reason), que se ejecuta siempre aquí sobre cualquiera que fuera el caso de prueba donde lo coloquemos. También muestra el epígrafe F pues, como se nos advierte en la excepción que se nos lanza en 2., se ha producido una AssertionError. En 3. se nos muestra la conclusión: FAILED, con un fallo y una omisión (failures=1, skipped=1).  LADRO: LAS CONDICIONES QUE DEBEMOS PASAR AL DECORADOR @unittest.skipIf(condition, reason) HAN DE SER, POR DECIRLO ASÍ, EXTERNAS AL PROPIO CÓDIGO DEL MARCO DE PRUEBAS DADO QUE NUESTRO DECORADOR ES UN MÉTODO ESTÁTICO Y, POR LO TANTO, AJENO A LA CLASE (EN NUESTRO EJEMPLO, TestString) POR LO QUE NO RECONOCE SUS INSTANCIAS. SI QUISIÉRAMOS, PONGAMOS POR CASO, ESTABLECER UNA CONDICIÓN (condition) CON self.palabra, COMO HACEMOS EN LOS CASOS DE PRUEBA, POR EJEMPLO, len(self.palabra) >= 7, NOS LANZARÍA UNA EXCEPCIÓN DE TIPO NameError: EL DECORADOR NO SABE QUÉ ES self.palabra. El decorador @unittest.skipUnless(condition, reason), que podemos traducir como "omite, a menos que...", reproduce un comportamiento análogo a @unittest.skipIf(condition, reason), por lo que ambos, como podemos comprobar en el ejemplo que sigue, son perfectamente intercambiables:   El cuarto y último de los decoradores disponibles, @unittest.expectedFailure, tal cual, sin zona de parámetros donde introducir un triste y famélico argumento ni nada que se le parezca, le da la vuelta al asunto, vira la tortilla: todo un giro copernicano: si lo aplicamos a un caso de prueba lo marcará como una falla, FAIL, que esperamos obtener, de tal modo que si la evaluación del caso de prueba deviene en fallo o contiene errores obtendrá éxito. Y si por el contrario supera la prueba, devendrá en fracaso. Vamos a verlo:  En esta ocasión situamos nuestro decorador @unittest.expectedFailure sobre el caso de prueba test inverso. En su cuerpo o ámbito utilizamos un método asertivo que evalúe si es verdadero (True) que nuestra contraseña (self.palabra, que almacena la cadena, "123abc") está compuesta sólo por dígitos. Ya sabemos que no es así porque contiene tres caracteres alfabéticos. Esperamos, pues, que no sea True y, por tanto, genere una falla (fail). Como éste es el requisito que espera el decorador @unittest.expectedFailure en 1. obtenemos una x, que apunta a este decorador y .s por la omisión efectuada por el decorador @unittest.skip(reason). En 2. se nos muestra la conclusión, OK, y se nos informa de que hemos tenido una omisión y un fallo esperado: (skipped=1, expected failures=1). En el ejemplo que sigue mostramos que el comportamiento es el mismo cuando en lugar de una falla (fail) obtenemos un error.  ¡Ah! Pero... ¡Mecachis! Ésto cambia cuando colocamos nuestro decorador @unittest.expectedFailure sobre un caso de prueba que, por lo normal, debería derivar en éxito. Veámoslo:  En 1. se nos muestra una u (unexpected) advirtiéndonos de que el decorador no ha actuado y la consiguiente s. del decorador @unittest.skip(reason). Ya en 2., ¡Horror!, no es un OK de lo más molón lo que nos aguarda sino un espectacular FAILED acusador, con la información pertinente delante: (skipped=1, unexpected failure=1).  Para finalizar con este apartado nos centramos a continuación sobre la forma de omitir, no un caso de prueba (o varios), sino toda una clase de prueba. Esto se consigue con facilidad simplemente colocando el decorador @unittest.skip(reason) por encima de la propia clase en lugar de por encima de los casos de prueba que queramos omitir. De esta forma, en lugar de omitir uno o varios casos de prueba omitimos todo un marco de pruebas que da Gloria verlo. 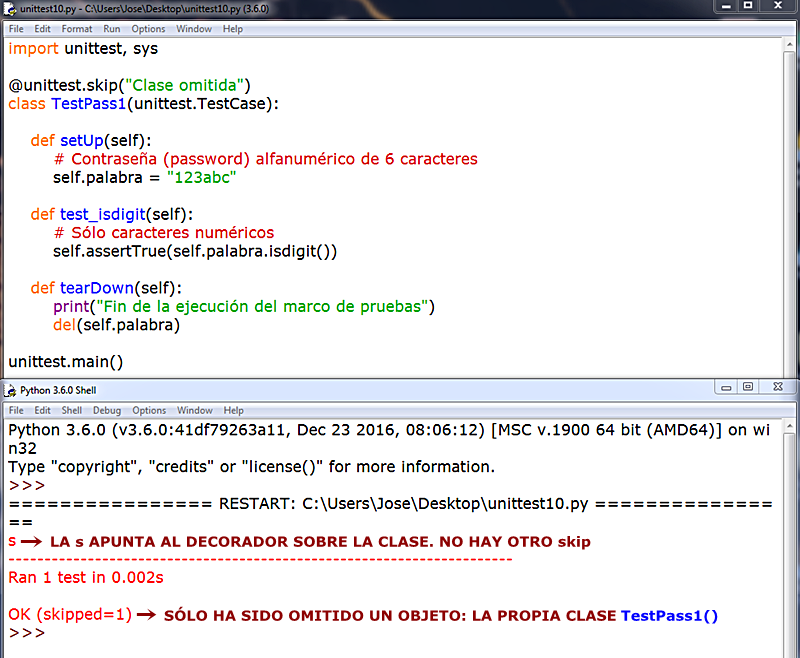 Quienes quieran profundizar con ejemplos más elaborados pueden visitar la siguiente dirección: https://www.programcreek.com/python/example/4814/unittest.skip IMPLEMENTACIÓN DE UN MARCO DE PRUEBAS PARA NUESTROS CÓDIGOS Muy importante tenerlo en cuenta: probamos métodos no las clases. Nuestro marco de pruebas siempre invoca métodos, no clases. Por eso, si hemos creado un módulo *.py que contiene una clase, llámese X(), que a su vez contiene tres métodos y queremos probarlos todos con nuestro corredor de pruebas unittest, debemos crear un fichero .py que sólo contenga esos tres métodos y "olvidarnos" del módulo *.py que contiene la clase X(). Vamos a ver paso a paso cómo hacer ésto. Partimos de un programa como el que mostramos a continuación, sencillo, para no volvernos locos, que consta de una única clase, MathLists(), y tres métodos para operar sobre secuencias a parte de su inicializador __init__(). Y nada más. Guardamos este fantástico programa en un archivo/módulo de Python que denominaremos operaciones.py.  En base a lo que hemos referido en el principio de este encabezado, creamos un nuevo fichero/módulo de Python que incluirá, sólo, los métodos de la clase, MathLists(). Y nada más. Denominaremos a éste archivo/módulo nuevo, operaciones_pruebas.py.   Para poder continuar con nuestras pruebas debemos generar una suerte de espacio o entorno de trabajo que nos permita hacerlo de una manera cómoda y sencilla. Esto nos obligará a crear un paquete, package, v. T1. PAQUETES (PACKAGES) DE PYTHON: ORDENANDO EL ARMARIO, al modo Python. Vamos a verlo con detenimiento: Desde nuestro IDLE de Python (o desde cualquier otro IDE que estemos usando en tanto nos permita hacerlo), seleccionamos la ruta File>Open en el menú superior, para que se nos muestre "descarnado" todo cuanto guarda en su interior el corazón de la versión de Python con la que estemos trabajando:   Colocamos el cursor en un espacio vacío a la derecha del todo, hacemos clic con el botón derecho para llamar al menú contextual y seleccionamos Nuevo, a continuación, Carpeta, para que nos genere automáticamente una carpeta o directorio nuevo en nuestro árbol de directorios de Python:  Esta nueva carpeta llevará por defecto el nombre de Nueva carpeta...  ... y que podemos renombrar como Area_pruebas:   Para convertir nuestra flamante carpeta Area_pruebas en un paquete de Python debemos crear una nueva subcarpeta dentro de la carpeta Area_pruebas, que podemos llamar OPERACIONES (en este caso hemos optado por escribir el nombre en mayúsculas, coincidiendo con el nombre del módulo original, operaciones.py, sobre el que vamos a aplicar nuestro corredor de pruebas unittest):     Debemos construir ahora un archivo/módulo de Python vacío, sin contenido de ningún tipo, al que, obligatoriamente, debemos llamar __init__.py:  En 1.,con el redondeo en amarillo, señalamos que hemos decidido crear el archivo en el Escritorio, por aquéllo de tenerlo más a mano, pero podemos elegir perfectamente en qué carpeta o directorio ubicarlo. Este archivo/módulo debemos colocarlo dentro de la subcarpeta OPERACIONES, en nuestro caso, arrastrando tan sólo el archivo __init__.py desde el Escritorio a la subcarpeta OPERACIONES:  Con esto ya tenemos nuestro paquete Python. Ahora, en esta misma carpeta OPERACIONES y a continuación del archivo __init__.py, insertamos nuestro archivo/módulo operaciones_pruebas.py que, recordemos, contiene sólo los métodos que hemos extraído desde la clase MathLists() a partir del fichero/módulo original operaciones.py.  Hecho esto toca elaborar nuestro marco de pruebas. Así crearemos sendos marcos de prueba por cada método que tengamos en el archivo/módulo operaciones_pruebas.py. Como tenemos tres métodos, crearemos, pues, tres marcos de prueba con su correspondiente entorno de prueba (Test Fixture) y que llamaremos en función del nombre de cada método. Así, nuestro tres marcos de prueba se llamarán: Test_Suma.py, Test_Potencia.py y Test_division.py. Mostramos a continuación cada uno de ellos:     Como las tres se basan en un mismo modelo de marco de pruebas, vamos a fijarnos en test_suma para conocer sus detalles, sabedores de que para las otras dos, test_potencia y test_division, las explicaciones del primero nos valdrán igualmente. En test_suma tras la importación pertinente del módulo unittest, importamos, en 1., nuestro paquete, package, OPERACIONES mediante una simple importación relativa desde la que llamamos a nuestro archivo/módulo operaciones_pruebas.py, que es donde tenemos nuestros métodos, recordemos, usando un alias, as, que llamamos op por aquéllo de acortar la cosa. A continuación, en 2,. modelizamos nuestra clase de pruebas que hemos dado en llamar TestSuma(), siendo en los dos ficheros siguientes TestPotencia() y TestDivision(). Ya en 3. comenzamos a construir nuestro entorno de pruebas, nuestro Test Fixture, instanciando el método setUp() donde insertamos nuestro elemento de prueba, una secuencia, que asignaremos a la variable self.secuencia. Elegimos una lista de enteros para probar: [1,2,3]. En 4. instanciamos un caso de prueba que llamamos test_suma(). En el cuerpo/ámbito del método declaramos una variable, s, que llamará sobre el alias op que apunta al archivo/módulo operaciones_pruebas.py mediante la sintaxis del punto al método suma que, en su zona de parámetros llevará la autorreferencia self y un parámetro obligatorio que representa una secuencia y que, en nuestro entorno de pruebas tenemos almacenado como elemento de prueba (self.secuencia) y que pasamos como tal al método suma.  ACLARACIÓN: EN NUESTRO EJEMPLO DEBEMOS PASAR LA AUTORREFERENCIA self COMO ARGUMENTO OBLIGATORIO EN EL CÓDIGO s = op.suma(self, self.secuencia) PORQUE EN EL ARCHIVO/MÓDULO ORIGINAL operaciones_pruebas.py, SI "NOS FIJAMOS, NOS LA HEMOS TRAÍDO" TAL CUAL DESDE EL ARCHIVO/MÓDULO ORIGINAL operaciones.py PARA DEJAR CLARO DE DÓNDE PROCEDEN ESTOS MÉTODOS. PERO TRANQUILAMENTE, SIN QUE SE NOS DESCOLOQUE EL FLEQUILLO, PODEMOS PRESCINDIR DEL PARÁMETRO self EN ESOS MISMOS MÉTODOS EN EL ARCHIVO/MÓDULO operaciones_pruebas.py YA QUE NO SE ENCUENTRAN LIGADAS A NUESTRA CLASE, EN CUYO CASO, TAMBIÉN DEBERÍAMOS PRESCINDIR DE LA AUTORREFERENCIA self EN LA ZONA DE PARÁMETROS DE suma() CUANDO LA INVOCAMOS EN EL CASO DE PRUEBA, QUEDANDO TAL QUE ASÍ: s = op.suma(self.secuencia). La última línea de código del caso de prueba test_suma() es la prueba en sí: self.assertEqual(s,7), donde se compara si son iguales el resultado de la ejecución del método suma() con la secuencia self.secuencia que le hemos pasado como argumento, y el número con el que lo queremos comparar, 7. Y ya en 5. llamamos al método tearDown() para que nos cierre el entorno de pruebas, el Test Fixture, y elimine de memoria el elemento de prueba self.secuencia. Bye, Bye. La pregunta que viene ahora es ... ¿Y dónde los colocamos? Pues en nuestro directorio/carpeta Area_pruebas, como vemos en la carpeta siguiente:  Ha llegado la hora... ¡Qué nervios! ¡Ay!: probemos nuestros códigos de prueba (valga la redundancia):    ¡Funciona! ¡Qué felicidad! ¡Qué subidón!  Introducimos ahora un esquema del árbol de directorios para que la estructura prototipo para todos los marcos de prueba que hagamos de este modo, nos quede más clara:  Proceder de este modo nos permite ir agregando diferentes casos de prueba en nuestros marcos siempre que deseemos, satisfechos sabedores de que se van a aplicar con diligencia sobre nuestros métodos e, incluso, probar nuevos métodos aquí y pasarle sus respectivos casos de prueba antes de incluirlos en el cuerpo de nuestra clase en el programa principal. Por si esto fuera poco, nos permite la reutilización de los marcos de prueba para aplicarlos sobre métodos similares que podamos incluir en otros programas que codifiquemos más adelante. Podemos modificar estos mismos marcos de prueba para adaptarlos a métodos parecidos pero no exactamente iguales. Para reforzar este concepto proponemos un nuevo ejemplo aplicado, en esta ocasión, sobre una string o cadena resultante de generar una contraseña con la clase Password() que tenemos en nuestro fichero passwd.py:   Generamos el preceptivo archivo/módulo con tan sólo el método de la clase Password() del módulo passwd.py y que hemos dado en llamar password(). Lo modificamos eliminando todas las autorreferencias dado que, una vez extraemos el método de la clase y lo introducimos en un fichero nuevo, sin clases, deja de ser una instancia de la clase donde se definió originalmente para convertirse en una simple función definida por el usuario, monda y lironda, sin autorreferencias self que valgan, e insertamos también las importaciones de módulos que necesitemos (para el ejemplo, re, para las expresiones regulares, v. EXPRESIONES REGULARES 1 y EXPRESIONES REGULARES 2). También debemos efectuar las modificaciones necesarias para desligarla de su clase original, matriz, como en nuestro ejemplo concreto, eliminamos toda referencia a la propiedad contra (self.contra). Este nuevo fichero que daremos en llamar psw.y nos quedaría así con sus modificaciones necesarias y comprobamos que funciona: 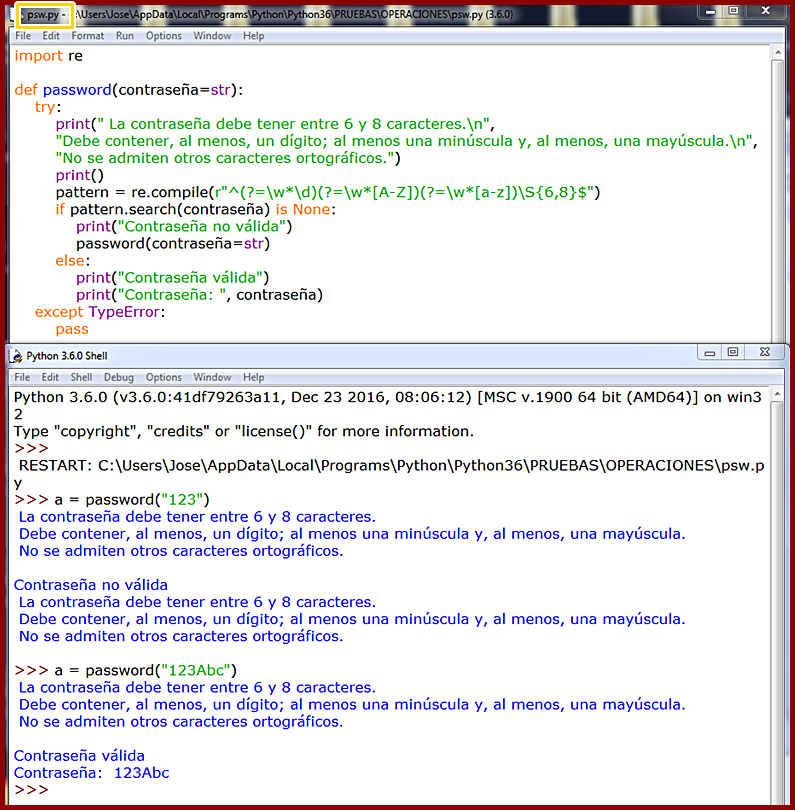 Procedemos a crear en nuestro "corazón de Python" la carpeta/directorio que necesitamos para construir nuestro paquete (package) de Python como ya hemos aprendido a hacerlo. Lo llamaremos PRUEBAS:  Dentro de esta nueva carpeta PRUEBAS creamos una subcarpeta que llamaremos OPERACIONES:  Dentro de esta subcarpeta OPERACIONES introducimos un archivo vacío de contenido que llamaremos __init__.py y con lo que construimos el paquete de Python que necesitamos, y nuestro archivo psw.py con la función definida password() que queremos probar:  A continuación, mostramos abajo nuestro fichero con la prueba unitaria y al que hemos denominado Test_password.py, con su clase de prueba, su marco de prueba y sus casos de prueba, todo dentro de un entorno de pruebas, el consabido Text Fixture.  Seguidamente, colocamos este fichero Test_password.py de prueba en su directorio correspondiente, dentro de la carpeta PRUEBAS y al mismo nivel que la subcarpeta OPERACIONES:  Y lo ejecutamos. Para no hacer demasiado extenso el ejemplo, eliminamos la parte reincidente que representan las impresiones en pantalla (las llamadas a la función print()):     https://es.wikipedia.org/wiki/Archivo:Plaza_del_Adelantado._San_Cristobal_de_La_Laguna._Tenerife._-_Flickr_-_Miguel._(respenda).jpg SUBPRUEBAS Este concepto de subpruebas tiene que ver con las iteraciones, lo que ya nos apunta que las pruebas se efectuarán sobre cada uno de los elementos de un iterable. Por eso hablamos de una prueba que se "divide" en subpruebas para evaluar cada elemento de un iterable: una lista, una tupla, etc. 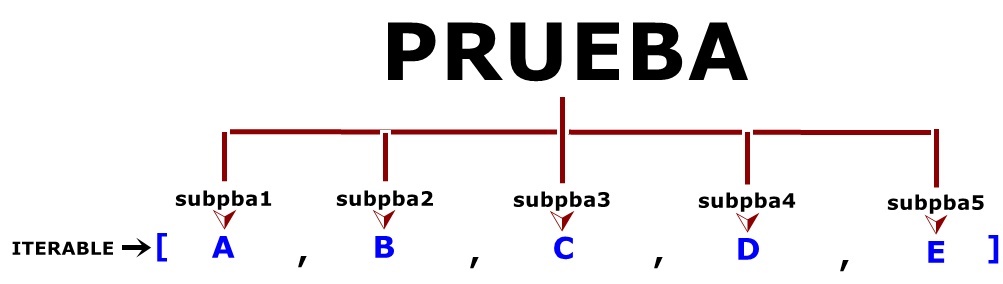  Además, en consonancia con todo esto, y tal como refiere el Sr. Dmitry Chukhin, en su sitio web de caktusgroup.com (https://www.caktusgroup.com/blog/2017/05/29/subtests-are-best/), conseguimos con ello que nuestras pruebas se ajusten al protocolo DRY (Don`t Repeat Yourself), lo que traducido al castellano, viene a ser: "No nos repitamos". Se trata de utilizar el método subTest() de la clase TestCase() de nuestro corredor de pruebas unittest de la librería estándar de Python, la que estamos desarrollando en esta página, como un administrador de contexto, lo que implica usar la sentencia with (v. T2. WITH: EN BUENA COMPAÑÍA) tal y como hacíamos cuando generábamos un Text Fixture, un entorno de pruebas. La estructura básica, esquematizada, es como sigue:  La "necesidad" de apoyarnos en las subpruebas obedece al hecho de que, si recurrimos directamente a la prueba sin establecer un administrador de contexto, with, donde insertar subpruebas, en el momento de la evaluación, el runtest, el corredor de pruebas, unittest, se detendría en el primer fallo, FAIL, que encontrase, con el agravante de que da por erróneo a la lista en sí, cuando el fallo lo ha producido un elemento, un ítem concreto dentro de la secuencia. Y como no lo maneja, no sabríamos identificar qué elemento ha sido el causante de la falla. Vemos un ejemplo que ilustra lo que acabamos de decir:  Pero si recurrimos a las subpruebas y establecemos el administrador de contexto e insertamos el método subTest(), que llevará como argumento único una autoasignación (tautología, en lógica proposicional), podemos sortear esta disyuntiva y obtener un análisis correcto, donde la prueba se efectuará ítem por ítem y, además, identificando todos aquellos elementos de la secuencia, por su nombre, que hayan incurrido en un fallo. Veamos ahora cómo "corregimos" el ejemplo anterior para que nos funcione divinamente:  Para finalizar con este apartado no podemos substraernos a mostrar el ejemplo que el propio Dmitry Chukhin propone en caktusgroup.com, misma página, y a quien recomendamos consultar para quienes deseen profundizar un poquito más en las subpruebas.   https://www.webtenerife.com/tenerife/la-isla/municipios/laguna/lugares-interes/palacio-nava.htm TestSuite() y TestLoader() Estos dos métodos, como Batman y Robin, como Starsky y Hutch, como Sonny Crockett y Ricardo Tubbs, siempre van y trabajan juntos. No se puede concebir el uno sin el otro. ¿Y para qué sirve esta pareja tan bien avenida? Para "juntar" pruebas que tengamos en distintos marcos de prueba, cargarlas (loader) y crear un único cuerpo cuerpo de pruebas (suite) que podamos aplicar sobre un elemento de prueba. Esto nos permite aplicar pruebas distintas procedentes de distintos módulos sobre un mismo elemento de prueba y, de alguna manera, supone una alternativa a la implementación habitual de casos de prueba que estudiamos un poco más atrás. Para lograr ésto, creamos un fichero/módulo Python que podemos llamar runner.py. En este fichero importamos nuestro corredor de pruebas (import unittest) y, justo a continuación, importamos los ficheros/módulos de Python donde tengamos codificados nuestros casos de prueba y que queramos aplicar. Vamos a basarnos en tres. Veámoslo:   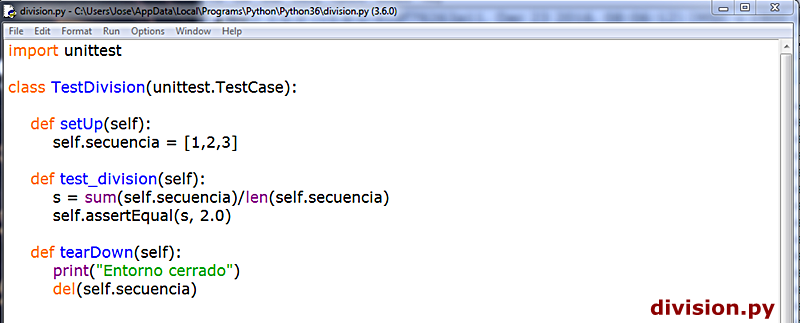  Obsérvese que ninguno de estos ficheros termina con la llamada a la autoejecución unittest.main(). Si así fuera, al llamarse luego desde nuestro módulo runner.py se nos devolvería un vacío porque los marcos de prueba no disponen de una cláusula return: actúan directamente sobre el caso de prueba, y como no hay ningún resultado devuelto, nuestra suite de pruebas runner.py no tiene nada que hacer. Para que el invento funcione es necesario que tanto los módulos de prueba (potencia.py, pares.py y division.py) como el módulo donde modelizamos nuestras clases para generar una suite de pruebas (que hemos dado en llamar runner.py, recordemos), se encuentran en el mismo directorio de Python:  Vamos a ver ahora cómo construir una suite de pruebas: runner.py.   https://www.webtenerife.com/tenerife/la-isla/municipios/laguna/lugares-interes/iglesia-santo-domingo-guzman.htm En 1. importamos el módulo unittest, nuestro corredor de pruebas, y en 2. importamos los módulos donde tenemos nuestros casos de prueba, en ambos casos, mediante importaciones absolutas. En 3. instanciamos un objeto que llamamos loader a partir de la clase TestLoader(). Esta clase es la encargada de cargar los casos de prueba que tengamos en nuestros módulos importados para tal fin (potencia.py, pares.py y division.py) y que, en nuestro caso, se corresponden con test_potencia(), test_pares() y test_division() respectivamente. Éstos serán los casos de prueba que el objeto loader se echará a la mochila y nos traerá, raudo y campante a nuestro módulo suite runner.py. En 4. instanciamos otro objeto que llamamos suite a partir de la clase TestSuite(). Esta clase es la encargada de construir la suite de pruebas propiamente dicha. Aquí se correrán mediante el método run() los casos de prueba que hayamos importado desde los diferentes módulos de prueba.  En 5. llamamos al método addTests() que pertenece a la clase TestSuite() y que aplicamos sobre el objeto suite que instanciamos de ella en 4.. Este método addTests() lleva un único argumento obligatorio: a través del método loadTestsFromModule() que como su nombre indica, carga las pruebas/casos de prueba (Tests) de un módulo. ¿De qué módulo? ¿De cuál? Pues de aquél cuyo nombre le pasemos a su vez como argumento; pares, potencia y division, respectivamente. ¿Qué hemos hecho, pues? Pues leyéndolo de corrido, sobre el objeto suite que se encarga de construir una suite de pruebas de lo más primorosa por mor de haberlo instanciado a partir de la clase TestSuite(), llamamos a todos los casos de prueba de cada uno de los distintos módulos de pruebas que el objeto loader ha podido cargar. ¿Capisci? Ahora que ya tenemos el asunto preparado y a punto de caramelo es necesario "mover" todo esto para que empiece a hacer su trabajo. Para conseguirlo, en 6. instanciamos un objeto runner a partir de la clase TextTestRunner(). Con esta llamada implementamos en nuestra suite un corredor de pruebas ad hoc para ejecutarlas. A esta clase se la suele pasar un argumento opcional, verbosity, que básicamente lo que hace es aumentar el detalle con que se muestran los resultados. Los valores pueden ser: 1, por defecto, 2 y 3. La mayoría de las veces su valor se establece en 2 ó 3. Finalmente, en 7., pulsamos el "botón". Declaramos una variable, result, que almacenará el resultado de la ejecución de nuestro corredor de pruebas básico, runner, llamando sobre él a través de la notación del punto, el dott method, al método run(), que llevará como único argumento obligatorio al objeto suite, el objeto que ha construido él solito nuestra propia suite de pruebas. Et voilà:   * La mayoría de las fotografías de este artículo han sido tomadas desde: https://www.solofondos.com/fondos-pantalla-san-cristobal-laguna.html |
Infinitas gracias por este excelente trabajo. sigo estudiando los materiales.
ResponderEliminarGracias a ti por dejar tu comentario. Ánimo con tus estudios.
Eliminar