 |
| SENDEROS DE LAURISILVA, EL PRIMITIVO BOSQUE DEL JURÁSICO, DEL QUE DESCIENDEN TODOS LOS DEMÁS BOSQUES HÚMEDOS DE EUROPA Y DE LA MAYOR PARTE DEL MUNDO, EN ANAGA, EN EL MONTE DEL AGUA, EN LOS ALTOS DE LA OROTAVA, ... EN TENERIFE. Y EN OTROS LUGARES DE LA ISLAS CANARIAS, MADEIRA Y ARCHIPIÉLAGO DE LAS AZORES. |
INTRODUCCIÓN
Nuestra intención en esta última página antes de comenzar con la Programación Orientada a Objetos es la de ofrecer pequeños códigos, simples scripts de andar por casa, que nos podrían ayudar a resolver de manera rápida y con la eficacia suficiente, algunas cuestiones de programación. Como un minimanual de "cómo hacer para que...". Cederemos el protagonismo a nuestros colaboradores peludos, que no paran de mover el rabito de pura ilusión, para que os lo enseñen.
Tengamos en cuenta que siempre que sus cabecitas se llenen de ideas, podrán añadirse códigos nuevos, por lo que deberíamos animarnos a consultar esta página de vez en cuando por si aparece algo de interés.
 Una buena idea es que tomemos los scripts que se nos presentan en esta página y nosotros mismos los modifiquemos añadiendo código muevo, respondiendo a preguntas como: "¿Qué sucedería si hacemos esto o lo otro?". Proceder de esta manera forma parte de la base del aprendizaje: probar cosas. Podremos luego guardar en algún sitio nuestros resultados (en una carpeta o en una simple libreta) para consultarlo cuando nos encontremos en situaciones similares o parecidas cuando estemos programando "de verdad", lo que nos librará de un par de jaquecas.
Una buena idea es que tomemos los scripts que se nos presentan en esta página y nosotros mismos los modifiquemos añadiendo código muevo, respondiendo a preguntas como: "¿Qué sucedería si hacemos esto o lo otro?". Proceder de esta manera forma parte de la base del aprendizaje: probar cosas. Podremos luego guardar en algún sitio nuestros resultados (en una carpeta o en una simple libreta) para consultarlo cuando nos encontremos en situaciones similares o parecidas cuando estemos programando "de verdad", lo que nos librará de un par de jaquecas.

USO DE continue PARA OPERAR SOBRE ITERABLES
Aquí podemos emplear la instrucción continue, que casi siempre se nos pasa desapercibida, para operar sobre los items de un iterable, una lista, por ejemplo, de una manera sencilla, rápida y eficaz, y con su puntito de elegancia, que también. En el primer ejemplo sumaremos sólo los números positivos de una lista dada, y en el segundo, lo mismo pero usando la función type() en un condicional (¡Sí! ¡La función type()!) para distinguir entre diferentes tipos de datos:


 AISLAR LA CLAVE DE SU VALOR EN UN DICCIONARIO
(modo grosero)
AISLAR LA CLAVE DE SU VALOR EN UN DICCIONARIO
(modo grosero)
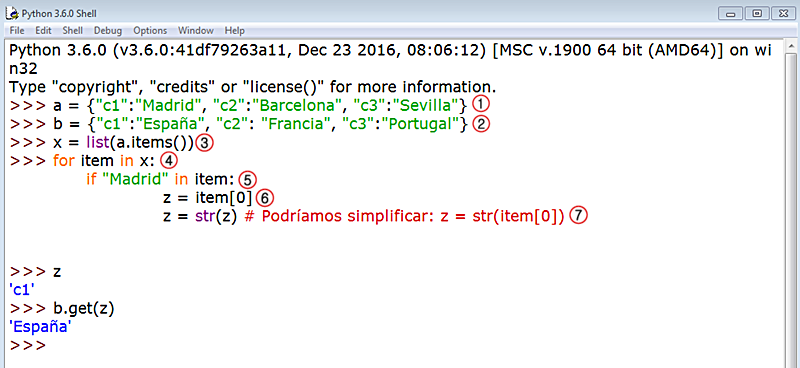
Os lo explico. En 1. y 2. declaramos sendos diccionarios, a y b, donde la clave (key) c1 está presente en ambos pero con valores distintos. En 3. declaramos una variable x que almacenará una lista con el objeto dict_items que devuelve la aplicación del método dict.items() del diccionario, y que aplicamos sobre el diccionario a. Así obtendremos una lista donde cada elemento será una 2-tupla: la clave (key) y su valor (value) asignado.
En 4. configuramos un bucle (loop) for/in para que itere sobre la lista x. Ahora introducimos en 5. un condicional if que evaluará si una determinada string está presente o no dentro de alguna de las 2-tupla. Esta string se corresponde con los valores asignados a la claves que queremos extraer. En 6., si la condición deviene True, declaramos una variable nueva, z, que almacenará el valor de la tupla donde se halle la string identificada por el condicional.
Como ya sabemos que todas nuestras tuplas contendrán sólo dos ítems (2-tupla, recordemos), los correspondientes a una clave y su valor asignado, si llamamos a item[0] obtendremos la clave que llevaba asignada esa misma string que hicimos "pasar" por el condicional. En 7. nos garantizamos que la clave extraída asuma como tipo de dato una string.
Finalmente, podemos comprobar en b.get(z) que el valor asignado a z nos sirve para extraer el valor asignado a la clave homónima en el diccionario b.

Así, si tuviéramos varios diccionarios con la misma clave, podríamos almacenar en una lista todos los valores asignados a ella. Para ver cosas más sofisticadas, podemos ir a la página de diccionarios y sus métodos.



BUCLES DE MÁXIMOS Y MÍNIMOS
En este sencillo script se mostrarán dos valores (salvo en el último paso del bucle) de acuerdo al recorrido que efectúa un loop for/in sobre un iterable, en este caso, una simple lista de números. El código mostrará un primer valor numérico que se corresponde con el elemento que es recorrido en ese momento por el iterador de acuerdo a su índice y que serán tantos como indique el len() del iterable, como podemos imaginar. El segundo se corresponde con el elemento de valor más alto de cuantos se hayan mostrado hasta el momento. Igual no sirve para nada pero, ... ¿a que es gracioso? ¡Ah!, y por supuesto, también se puede hacer para obtener el menor de cada vez.
MAYOR:

MENOR:



EJEMPLO DE LLAMADA A UNA FUNCIÓN DESDE EL CUERPO DE OTRA FUNCIÓN CON globals():
En este ejemplo definimos una función a la que llamaremos fun y en la que pedimos que el usuario introduzca una palabra (una string o cadena), y nos devolverá el tamaño (longitud) de la palabra.
A continuación, definimos una segunda función a la que vamos a llamar fun2. En ella declaramos una variable p, a la que asignamos la llamada a la función fun() a través de globals(), que lleva adjunta y entre corchetes (realmente, genera una suerte de diccionario donde la clave es el nombre de la función) el nombre de la función pasado com una string. Junto a los corchetes, pasamos los paréntesis (zona de parámetros) que indica que dicho nombre atiende a una función. Declaramos a continuación una segunda variable, m, que almacenará el resultado de la ejecución de la primera y lo multiplicará por 5, por hacer algo, vamos. Ésto será lo que nos devuelva.



USO DE LA CLÁUSULA else EN UN BUCLE for/in:
En el ejemplo que viene a continuación vamos a escribir un código extremadamente sencillo para validar una dirección de correo electrónico en función de que contenga o no el símbolo arroba, @. Evidentemente, con esto no conseguiríamos validar de manera eficiente ningún correo porque faltarían otros parámetros a valorar, como la presencia o no del punto que especifica la extensión, por ejemplo. Podemos encontrar un buen sistema de verificación de correo electrónico apoyándonos en las expresiones regulares 1 y expresiones regulares 2 en este mismo manual.



FILTRADO SIMPLE PARA BÚSQUEDAS
Tomaremos como ejemplo una lista sencilla de cadenas de texto. Usaremos un bucle for/in para recorrerla a la caza y captura de coincidencias y las mostraremos en pantalla con la función preconstruida print().



CONVERTIR VARIOS DATOS INTRODUCIDOS DE UNA VEZ A TRAVÉS DE UN input() EN UNA LISTA PARA PODER ITERAR SOBRE ELLOS
En este caso vamos a ver cómo podemos convertir una entrada de varios datos a la vez en una lista, primero sin método alguno y después a través del método split() de las string. Este ejemplo es muy importante que lo memoricemos (o lo tengamos a mano, como quien dice), porque es muy socorrido y lo emplearemos en multitud de programas que diseñemos. Ya lo veréis.
En el primer caso, sólo sirve para deconstruir en sus partes mínimas integrantes una secuencia de datos ingresadas por input(), ¡ojo!, por lo que, por ejemplo, si queremos separar números, sólo nos sirven dígitos simples, entre 0 y 9; o en el caso de que pasemos cadenas de texto, strings, cada uno de sus caracteres literales. Con el método split() se supera esta condición y obtenemos los resultados que queremos sin importar el tamaño de las entradas.
¡Ah! Se me olvidaba: recordemos que todo dato ingresado a través de un input() es de tipo string por defecto, por lo que si queremos cambiar el tipo de dato, tendremos que usar el conversor que necesitemos, en el ejemplo, int(), para obtener número enteros.

LO MISMO PERO USANDO ESPACIOS EN BLANCO EN LUGAR DE COMAS PARA INTRODUCIR LOS DATOS

CON EL MÉTODO split() DE LAS STRING:



DESGLOSAR UN TEXTO EN UN PÁRRAFO ÚNICO CON UN NÚMERO DETERMINADO DE CARACTERES
En esta ocasión mostraremos una manera entre otras de construir un párrafo con el recurso de un función definida por su peludo servidor con un número determinado de caracteres literales por línea mediante el uso de slices, y el método replace() de las string.
El texto que queramos pasar lo asignaremos a una variable que pasaremos, a su vez, como argumento de la función para hacerla más flexible. Usaremos range() para determinar el número de líneas que debe tener el párrafo, por lo que debemos tener cuidado de que no se nos corte el texto: así conviene añadir alguna línea más según la longitud que hayamos dispuesto para cada una de ellas, aunque fuera calculando a ojo.
No es una gran cosa, podría servir para textos en inglés, pero quien quiera perfeccionar el código para mejorarlo en la sintaxis del castellano, adelante. Ése es el reto.

 |
| ACANTILADOS DE LOS GIGANTES. ALGUNAS DE SUS PAREDES TIENE MÁS DE 600 METROS DE ALTURA Y SE PROLONGAN DURANTE VARIOS KILÓMETROS HACIA EL NORTE HASTA ENLAZAR CON EL MACIZO DE TENO. AL FONDO, ENTRE LA NIEBLA, PUEDE DISTINGUIRSE LA LENGUA DE TIERRA PLANA QUE CONFORMA LA PLATAFORMA LÁVICA DE TENO, JUSTO EN EL ÁNGULO DONDE LA ISLA GIRA HACIA EL ESTE. LOS GUANCHES, ANTIGUOS ABORÍGENES DE LA ISLA, EN EL REINO OCCIDENTAL DE DAUTE, CREÍAN QUE ESTE ERA EL LÍMITE DEL MUNDO Y QUE NO EXISTÍA NADA MÁS ALLÁ DE ESTOS PAREDONES. MUNICIPIO DE SANTIAGO DEL TEIDE. TENERIFE. |

OTRA FORMA DE BUSCADOR EN UN DICCIONARIO RECORRIENDO UNA LISTA COMO VALOR
Aquí traemos un sencillito script de búsqueda simple por caracteres literarios de un valor concreto dentro de una lista que, a su vez, es el valor de sendas claves de un diccionario común y corriente, de los de toda la vida en Python. Veremos bucles for/in anidados (2 niveles) y un condicional if. Y con esto y un simple método de los diccionarios, ya está. Por supuesto, funciona también con palabras incompletas, pero decididamente, tal y como se muestra en el segundo ejemplo, no parece que sea la mejor opción.




EJEMPLOS DE USO DE FUNCIONES ANIDADAS
Un par de ejemplos de uso de funciones anidadas. El primero muy simple para ver y entender la mecánica del asunto. Y el segundo, más elaborado, para comprobar su uso en un supuesto "real". Tengamos en cuenta que uno de los aspectos fundamentales del uso de funciones anidadas está en las autollamadas o retrollamadas, los callbacks, que es lo que permite que las funciones anidadas... funcionen.




USO DEL loop while PARA REINICIAR INDEFINIDAMENTE UN input() HASTA OBTENER LA ENTRADA EN EL FORMATO DESEADO
Mostraremos a continuación un uso "bruto" del bucle dinámico while para obtener una entrada de datos con el formato especificado por el programa. Este tipo de situaciones suelen resolverse de manera optimizada echando mano de las expresiones regulares, pero si las condiciones de entrada son simples y no nos requiere más de un par de líneas de código, pues vale.

Mostramos a continuación cómo conseguir lo mismo utilizando una expresión regular. En este caso debemos cambiar el condicional dinámico while por if:



BÚSQUEDA DE ARCHIVOS EN EL DISCO DURO
En esta ocasión traemos un script muy útil que nos permite escanear nuestro disco duro a la búsqueda de un archivo en base a su nombre y extensión. Este dato se convierte en un patrón de búsqueda, en una suerte de filtro, de tal modo que el programa nos mostrará las coincidencias y el número de archivos coincidentes con el patrón.
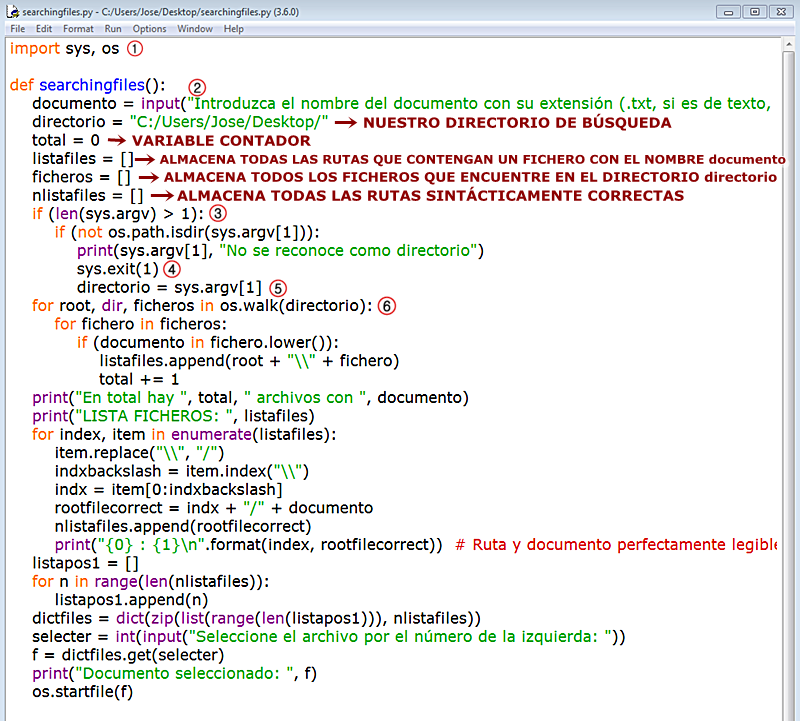
En 1. efectuamos las importaciones necesarias.
En 2. introducimos el fichero que queremos localizar con su correspondiente extensión. En caso de que omitamos la extensión , buscará todas las coincidencias.
En 3. tenemos un condicional mediante el cual obtendremos un iterable con todos los argumentos pasados por la línea de comandos. Si éste es mayor que 1 y, además no se trata de un directorio válido, se nos mostrará un mensaje de error, con lo que saldríamos del programa, en 4. El valor de directorio pasa a ser el segundo ítem de la lista, en 5., que será el nuevo directorio donde buscar (si se proporciona más de uno).
En 6. es donde, realmente, se inicia el proceso de búsqueda propiamente dicho: raíz, directorio base, y lista de ficheros que comparten el mismo nombre (fichero) leyendo a lo largo (os.walk) del directorio ("C:/Users/Jose/Desktop").
Recurrimos a la función enumerate() de orden superior para mostrar un seleccionador de ficheros donde elegir el que nos interesa. Finalmente, éste se nos abrirá en una ventana a parte de nuestro escritorio mediante la función os.startfile(filename).
Veámoslo:





EXTRACCIÓN Y MANIPULACIÓN DE DATOS NUMÉRICOS DESDE UNA string
En esta ocasión (y probablemente no sea la única, me lo huelo yo) vamos a recurrir a los métodos de las strings (recordemos, de las cadenas) para extraer datos concretos de una cadena, en este caso, de números, usando caracteres literales como "trampolines" para ello. Una vez tengamos los datos numéricos convertidos al tipo de dato que queramos obtener, por ejemplo, entero, decimal, octal, etc., procederemos a manipularlos. En nuestro ejemplo partiremos de un par de cadenas almacenadas en una lista.

Vamos a introducir ahora una variante interesante. Veremos por qué: cuando trabajemos con bases de datos nos encontraremos con que el tipo de datos que podemos almacenar es muy limitado, básicamente, porque no almacenan colecciones de datos, ergo, no almacenan listas, tuplas, conjuntos y diccionarios, que son las colecciones más recurrentes en Python.
¡Diantre! ¿Y si queremos guardar una colección o secuencia de datos en un único campo? La solución más rápida, si no queremos crear un número excesivo de campos en nuestra tabla, es convertir nuestra colección en una string, en una cadena de texto, (que en la mayoría de las bases de datos se traduce como tipo de dato varchar, esto es, varchar = string) y que el lenguaje SQL en que se apoyan la mayoría de las bases de datos que en el mundo hay y habrán sí admite.
El "problema" surge cuando, por ejemplo, queremos hacer una actualización de los datos o valores contenidos en esa lista y necesitamos recuperarlos tal cual eran originariamente, por ejemplo, una lista de números enteros, para poder operar sobre ellos.
Pues bien aquí mostramos una solución para una lista de números enteros, del 1 al 7, que hemos convertido directamente en una lista para insertarlo en un campo dentro de una tabla de datos. El procedimiento es más o menos similar para cualquier otra colección de datos que hayamos "cadenizado".

Existe otra forma de extraer datos numéricos de una string, pero de manera mucho más limitada, por lo que su uso solo se recomienda para extraer valores numéricos simples, y es a través del método isdigit() de las strings. Todos los métodos booleanos de las cadenas (todos los que empiezan por la "pregunta" is..., como isdigit(), propiamente dicho, isalpha(), islower(), etc.), precisamente por ser booleanos, admiten muy bien el control de los condicionales if y while, lo que nos permite recurrir a ellos para extraer, por ejemplo, las mayúsculas o minúsculas de una cadena, los caracteres no numéricos de una cadena (justo lo contrario de lo que vamos a mostrar en el ejemplo), los caracteres literales que no sean espacios en blanco, etc. Es todo un mundo de posibilidades que conviene que exploremos para contar con recursos a mano para cuando llegue el momento de programar en "serio". Os lo recomiendo yo, que acabo de salir de la peluquería...
   |
| INVIERNO AZUL EN EL PARQUE NACIONAL DE LAS CAÑADAS DEL TEIDE, CON EL TEIDE Y EL PICO VIEJO AL FONDO, UNA CRESTERÍA DE PINAR, PENDIENTE DE LAVA NEGRA Y LA CARRETERA QUE CRUZA EL PARQUE DE EXTREMO A EXTREMO. |

USO DEL MÉTODO count() DE LAS LISTAS EN COMBINACIÓN DE LA FUNCIÓN zip() DE ORDEN SUPERIOR PARA DETERMINAR EL NÚMERO DE REPETICIONES DE UN ÍTEM EN UNA LISTA
¡Guau! Con un título como éste no se me ocurre nada más que decir. Adiós, me voy a dormir...



ORDENAR DE MAYOR A MENOR UNA LISTA
En esta ocasión vamos a crear una lista cuyos elementos serán 2-tupla, por aquéllo de complicar un poco la cosa, aunque el formato es perfectamente extrapolable a situaciones similares (podemos practicar un poco con el código, darle un par de vueltas, para comprobarlo). El ordenamiento lo haremos en base al dígito de la tupla (su item[1], vamos). En nuestro ejemplo, usaremos un nombre de fruta como primer elemento de la tupla, y el número de piezas en nuestro frutero en la cocina, como segundo. ¡Uy!¡Qué hambre!
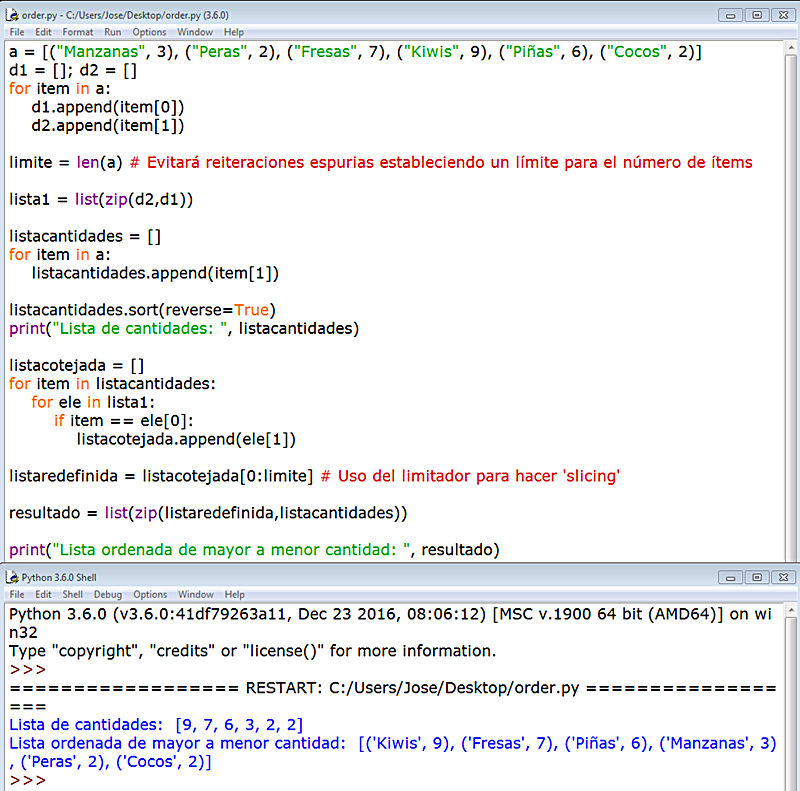
¡Ojo! Si tenemos algún elemento repetido, como es el caso de nuestra lista a, donde 'Peras' y 'Cocos' coinciden en cantidad, no debemos usar diccionarios, que sería una forma aún más fácil e intuitiva de hacerlo porque, como ya sabemos, igual que ocurre con los conjuntos, set, eliminan los ítems repetidos. Lo vemos:


Aquí mostramos una opción para devolver sendos iterables en base a una información suministrada por la devolución de una función zip() de orden superior. De ella extraeremos datos para ofrecer una información coherente a un usuario potencial discriminando entre lugares (Talleres ... ) y categorías (EPF, EPD y EPE). En este caso, sabemos de antemano uno de los datos: las categorías, y no así los lugares que pueden ser muchos y variados. La devolución final es un conjunto, un tipo de dato set, pero sería mejor mostrarlo como una lista o como una cadena de caracteres literales con las correspondientes funciones conversoras list() o str().


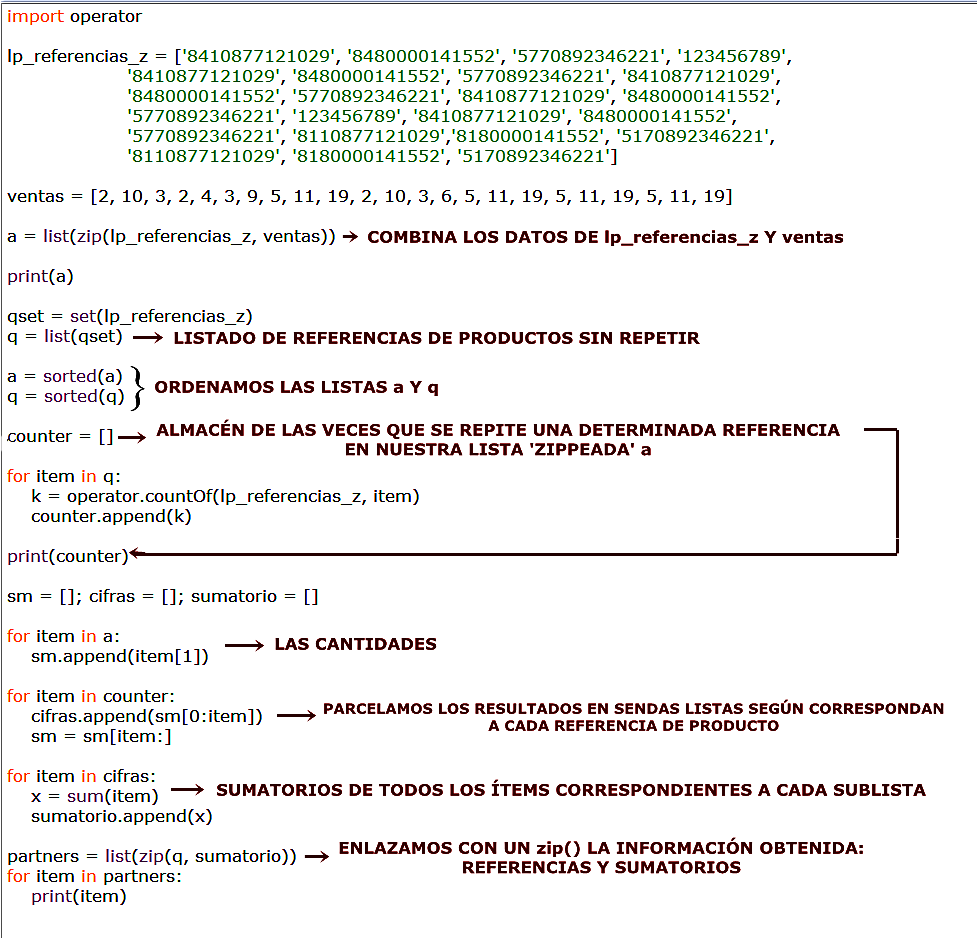
Veamos ahora cómo hacerlo cuando no sabemos de antemano los datos con los que vamos a tener que trabajar. Partiremos de una lista de referencias (código de barras) de productos y sus ventas en una tienda normal y corriente a modo de ejemplo.



INPUTS CON VARIOS ELEMENTOS EN UNA MISMA ENTRADA Y SU POSTERIOR ENLISTADO PARA MANIPULARLOS CUANDO QUERAMOS
Ahora procederemos a ver cómo podemos permitir al usuario que ingrese varias entradas a través de un único input (input()), una vez obtenidos, introducirlos en una lista por si queremos manipularlos posteriormente, por ejemplo, iterando sobre ellos. Es importante tener en cuenta que los datos se enlistarán en el mismo orden en que el usuario introdujo los datos.

1. Obviamente, podemos simplificar el script anteponiendo el conversor int() envolviendo a la función input(): nums = int(input("Introduce varios números enteros... ")).


LISTAR ELEMENTOS (ORDENADOS) DE UNA LISTA
En esta ocasión nos basaremos en una lista de datos (secuencia) normal y corriente con el propósito de enlistar (esto es, hacer sendos subconjuntos) de sus propios datos, generando así lista de dos niveles: el nivel principal, la lista madre, por así decirlo, y el nivel secundario, que en nuestro ejemplo estará formado por tres listas interiores, cada una de ellas, con tres datos como elementos. Decimos "ordenados" en el título porque aplicaremos técnicas de slicing, es decir, "troceado", para conseguirlo, y nos resultará más fácil a la hora de escribir código si la técnica es la misma para toda la lista.



SUBCONJUNTO DE DATOS NO REPETIDOS ENTRE DOS LISTAS
Vamos con dos técnicas distintas, ambas lógicas, pero la primera más intuitiva que la segunda, para crear una tercera lista que contenga datos que no se repitan entre dos listas dadas. Claramente, también podemos efectuar el proceso contrario, es decir, crear un subconjunto de datos repetidos con sólo modificar las condiciones.



ORDENAR UN DICCIONARIO
En alguna ocasión, querríamos mostrar (u obtener para manipular posteriormente) un diccionario con sus elementos ordenados de alguna manera, lo que "vulnera" la naturaleza misma de los diccionarios (y conjuntos), esto es, que almacenan los datos de manera desordenada (aleatoria), razón por la cual no es posible iterar sobre ellos. Para conseguir el "milagro" debemos llamar al módulo operator de la librería estándar de Python y hacer uso de la función integrada sorted(). Vamos a verlo.


SEGMENTAR EN BASE A UN CRITERIO DE COINCIDENCIA ENTRE DOS LISTADOS zip()
Partimos de dos listas que queremos combinar de tal modo que al ítem con el índice 0 de la primera de nuestras listas le corresponda su equivalente de la segunda; que al ítem con el índice 1 de la primera de nuestras listas le corresponda su equivalente de la segunda; y así sucesivamente. Para eso tenemos la función zip() de orden superior, que nos resolverá el problema y a la que yo le ladro con fervor. Después, agruparemos las coincidentes en base al criterio de su nombre que, evidentemente, será una cadena.

 |
| FORMACIÓN LÁVICA CONOCIDA COMO "ZAPATILLA DE LA REINA", EN EL PARQUE NACIONAL DE LAS CAÑADAS DEL TEIDE, DURANTE UNA CLARA NOCHE DE PRIMAVERA. AL FONDO, EN EL CIELO, LA VÍA LÁCTEA. EN PRIMER TÉRMINO, EN EL ÁNGULO INFERIOR DERECHO, UNA RETAMA A PUNTO DE FLORECER. |

CONTAR EL NÚMERO DE ELEMENTOS QUE SE REPITEN EN UNA LISTA A PARTIR DE OTRA LISTA
Con este script que os traigo ahora os muestro cómo podemos contar el número de ítems que se repiten en una lista cualquiera dada una segunda lista que nos servirá de control: en esta segunda se nos dice de qué elemento se trata y, a partir de aquí, se nos informará sobre cuántas veces se repite ese mismo elemento en la lista primera. ¡Ah! Y la función integrada zip(), claro. Vamos a verlo:



OFRECER UNA MUESTRA NUMERADA DE POSIBILIDADES Y SU POSTERIOR ELECCIÓN POR UN USUARIO MEDIANTE input()
Vamos a mostrar cómo ofrecer a un usuario potencial una lista de opciones numeradas para su selección de manera sencilla. Una vez seleccionada el ítem que se quiere, y esto depende de vosotros mismos, podréis establecer la bifurcación necesaria para atender cada caso mediante el condicional if. Como vamos a crear las listas fuera del ámbito de la función que definiremos, tendremos que usar la cláusula global, y una chispita de zip() para no perder las costumbres:
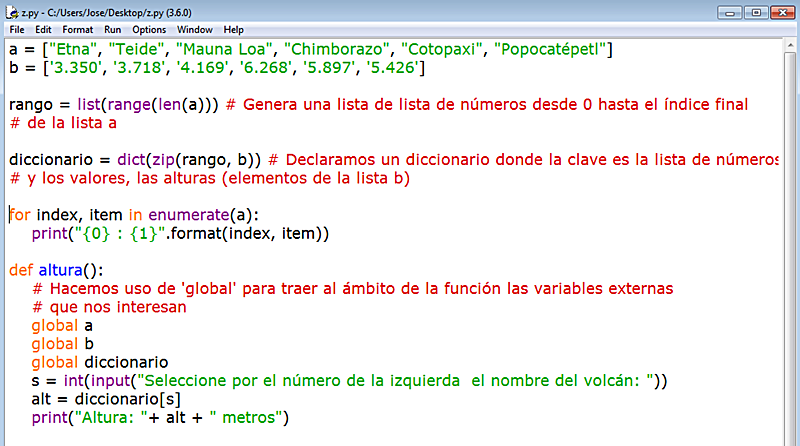
Y ahora comprobamos que funcione...



SUSTITUCIÓN DE ESPACIOS EN BLANCO POR CARÁCTER '_'
Lo que traigo a continuación parece una bobería. Y lo es. Pero es una bobería importante. Me explico con un par de ladridos: cuando trabajemos con base de datos, por ejemplo, SQLITE, dado que la librería estándar de Python nos provee de un módulo excelente, sqlite3, para manejarnos en esta formulación, nos encontraremos que entre unos pocos tipos de datos admitidos tendremos el tipo varchar que equivale a nuestras strings, cadenas, de Python.
Si, una vez insertado un dato pasado como varchar (string) en una tabla cualquiera de nuestra base de datos, por ejemplo, una tabla denominada EMPLEADOS con una columna o campo, que así se llama técnicamente, que hemos llamado nombres, entre otros campos más, y pasamos como varchar (string) el nombre María a este mismo campo nombres, si queremos extraer para mostrar al usuario o actualizar la información el resto de datos de la tabla en relación con este nombre (anda, querida tabla EMPLEADOS, muéstrame todos los datos o, registros, que así también se llama técnicamente, relacionados con este nombre María), con lo que el motor de la base de datos buscará el argumento que le hemos indicado: María, en su campo correspondiente, nombres, y si encuentra la concordancia nos mostrará todos los registros almacenados en el resto de campos, como apellidos, id, email y móvil, por ejemplo, de tal modo que nos saldría algo como ésto: 3 (id), María (nombre) García (apellidos), mariagarcia@todomail.com (email) y 978123123321321 (móvil). ¡Qué bien! ¿Verdad? Todo ha funcionado correctamente. 👍).
¡Ah! Pero no todos son flores y trigo en los campos del Señor: si en vez de insertar un nombre simple como María hubiéramos insertado un nombre compuesto, como Ana María o María de la Encarnación, por ejemplo, con uno o varios espacios en blanco entre los caracteres literales... ¡Ay! La base de datos se revuelve como una fiera enloquecida y no reconoce el dato (registro). Y como no lo reconoce, no puede establecer concordancias y no podrá operar 😱.
Sucintamente esto se debe a que Python, como cualquier otro lenguaje de programación, según la sintaxis de cada cuál, reconoce como string o cadena cualquier cadena de caracteres literales, incluidos todos los espacios en blanco que queramos, como una única unidad siempre y cuando se encuentre entre una, dos o tres comillas (quotes) de apertura antes del primer carácter y su equivalente, una, dos o tres comillas, justo a continuación del último carácter.
Pero el lenguaje SQL sólo reconoce como varchar (string) aquéllo que le indiquemos expresamente que queremos pasarlo como tal, como varchar, sin tener en cuenta las comillas, por lo que SQL interpretará cada espacio en blanco como el final de una varchar (string) por muchas comillas que le pasemos y no como una única unidad de principio a fin.
Y para esto nos servirá transformar los espacios en blanco de nuestras cadenas Python en guiones bajos para que SQL interprete que se trata de una única unidad y pueda devolvernos el resultado esperado:
- 'María' (Python) ⇰ María (SQL) ✔️
- 'María del Rosario' (Python) ⇰ María (SQL) ❌ (No hay concordancia y da error)
- 'María_del_Rosario' (Python) ⇰ María_del_Rosario (SQL) ✔️
Veamos un sencillísimo script que resuelve primorosamente este caso.



EXTRAER DE VARIAS LISTAS SUS ELEMENTOS POR LA COINCIDENCIA DE SUS ÍNDICES E INSERTARLOS EN UNA LISTA.
Vamos a imaginarnos el siguiente caso: somos los afortunados propietarios de una tienda de comestibles donde nos dedicamos a vender frutas, verduras y cereales frescos, de producción ecológica y sostenible con el medio ambiente. Y nuestra tienda lleva abierta al público desde el año 2015, teniendo registros de ventas totales por cada año de frutas, verduras y cereales hasta el año 2019, cinco años en total, en kilos. Para comprobar las cantidades (ventas) que hemos obtenido en cada uno de esos cinco años por cada género de ventas (frutas, verduras, cereales) podemos proceder del siguiente modo:

En 1. debemos añadir una tupla vacía, (), como segundo argumento obligatorio de la función zip() de orden superior que, recordemos, siempre debe llevar dos o más iterables. Como sólo pasamos uno, una tupla con los cinco años de nuestro registro de ventas, debemos completar el requisito con la mencionada tupla vacía.
En 2. insertamos en la lista apilado_por_genero un trozo (rebanada, slice) de la lista apilado y que se corresponde con el tamaño/longitud de la lista anyos (de 0 a length). A continuación, en la línea de código siguiente, decimos que la nueva lista apilado va a ser la misma lista pero habiendo suprimido la rebanada que acabamos de introducir en la lista apilado_por_genero, por lo que usamos la sintaxis apilado[length:] de manera que la nueva lista apilado, en virtud del operador = de asignación, pasa a ser la parte, el segmento, de la lista original apilado que vaya desde el índice señalado por length hasta el final de la misma.
Veamos ahora el resultado de la ejecución de nuestro código:

En 1. tenemos la lista original, en crudo, que obtenemos sin segmentar por índices.
En 2. tenemos una impresión de manera que ya podemos ver el resultado con las ventas de cada uno de los cinco años, en formato lista, para cada género: Frutas, Verduras y Cereales.
A título perruno, yo hubiera preferido que fuera pienso, salchichas y lonchas de mortadela en lugar de frutas, verduras y cereales... La próxima vez.


ELIMINAR ELEMENTOS REPETIDOS EN UNA LISTA CUYOS ELEMENTOS SON TODOS LISTAS.
(LISTAS DE DOS NIVELES)
Ya sabemos que para eliminar elementos repetidos de una lista dada podemos recurrir a la función integrada conversora set() que se encarga específicamente de ello. Pero cuando los elementos de la lista que queremos simplificar son, a su vez, listas (lo que se conoce como listas de segundo nivel), la función set() no sabe muy bien qué hacer. Veámoslo:

Sin embargo, podemos eliminar elementos repetidos en una lista de listas saltándonos la función set() y recurrir a una fórmula alternativa mediante una lista receptora, y un par de métodos propios de las listas. Tan sencillo como esto:

Sencillo, ¿no?


APROVECHAR EL MÉTODO split() DE LAS STRINGS PARA REPARTIR VALORES ENTRE SENDAS VARIABLES.
Este pequeño código, muy pequeñito, sí, nos permite hacer splitting, es decir, "dividir, escindir", en este caso, una string o cadena de caracteres literales para obtener datos/valores de ellas y que podamos asignar a distintas variables tan lindamente, por ejemplo, una cadena que contiene diferentes notas de evaluación y que queremos asignar a los alumnos correspondientes, eso sí, manteniendo el orden de caracteres en que se nos muestra de manera original nuestra string.


CONSTRUIR UNA LISTA 'ESPEJO' DE OTRA LISTA GENERANDO UNA ESPECIE DE TRASVASE DE DATOS A OTRA LISTA ELIMINÁNDOLOS A LA VEZ DE LA LISTA ORIGINAL.
Vamos a crear listas espejo, esto es, listas que tiene los mismos elementos que otras sobre las que se "reflejan". Sabemos ya que para esto Python nos provee del método copy() de las listas y que, en apariencia, funciona de una manera muy simple. Veamos un ejemplo:

Y vamos a ver ahora cómo podemos obtener un resultado similar sin utilizar el método copy(). En este caso, además de crear una lista espejo VACIAMOS la lista original que queda reducida a una lista vacía, como si le aplicáramos el método clear(), también de las listas. Parece algo fácil de hacer e, incluso, intuitivo. Pero en mi hociquito me da que no lo es tanto...


CONSEGUIR DE MANERA SENCILLA UN SLICING DINÁMICO.
En esta ocasión vamos a ver cómo con unas pocas y sencillas líneas de código podemos trocear una lista de datos, consiguiendo construir sin que tengamos que hacer nada, tantas sublistas con n elementos cada una como queramos, con el único recurso del condicional dinámico while y la técnica habitual de troceado (slicing) que ya conocemos. Vamos allá.

La magia comienza en 1., cuando establecemos el tamaño de la primera sublista entre el primer elemento de la lista de partida a y su índice final, que será el valor de n que, en este caso, es 3, y que asignamos a la variable x, que guardará con amor de madre nuestra primera sublista de a. Ya en 2. y, ¡ojo!, al mismo nivel que el iterador for/in, es decir, fuera ya de su ámbito, ELIMINAMOS de la lista de partida a ese mismo trozo (slice) que acabamos de crear (nuestra primera sublista x), con lo cual nuestra lista a será ahora como sigue: a = ["d", "e", "f", "g", "h", "i", "j", "k"]. ¡Y ya está! El bucle dinámico while seguirá funcionando mientras hayan elementos en a. Cuando ya no quede ninguno, simplemente, se detendrá.
Esto es válido para cualquier número de elementos en a. Vemos abajo cómo tenemos una lista de 15 elementos y nuestro valor de contador n es 4: Todas las sublistas tendrán cuatro elementos salvo la última que tendrá sólo tres.


CALCULAR EL NÚMERO DE DÍAS QUE SE CONTIENEN ENTRE DOS FECHA EN UN MISMO AÑO
Vamos a mostrar aquí un script muy sencillo y cortito para calcular el número total de días que hay entre un día de un mes en concreto y otro día de otro mes (o del mismo mes) , eso sí, dentro de un mismo año. Para hacer esto necesitamos importar la librería datetime de Python de la que llamaremos al objeto date que nos permitirá obtener el tipo de dato que necesitamos. En la variables a y b pasamos los datos que necesitamos: en a la fecha de inicio, donde insertamos el año, el mes y el día, separados por comas; y en b lo propio para la fecha final. En c almacenamos el resultado de la diferencia que será un objeto de tipo date. Como no nos interesa obtener valores negativos, usamos como filtro la función integrada abs(). En la variable numberdays almacenamos la conversión a cadena del objeto c (que, recordemos, es un objeto tipo date) para poder luego, a través de la variable total, aplicarle una técnica de slicing (rebanada). Finalmente, el resultado lo mostramos como entero con el concurso de la función conversora int().

🔔 Esperamos que este manual continúe, si Dios quiere, en un blog nuevo construido a parte y ex profeso, una vez acabemos de ver todo lo concerniente a la Programación Orientada a Objetos, dedicado a las librerías más usadas en Python donde repasaremos códigos como el que acabamos de ver.

EXTRACCIÓN DE DATOS CONCRETOS DE UN FICHERO
En esta ocasión vamos a ver cómo extraer un determinado tipo de información a partir de los datos aportados desde un fichero y separarlos. Tomaremos como ejemplo un fichero que llamamos z, con extensión .txt, esto es, un fichero de texto plano, z.txt, del mismo bloc de notas de Windows. Es importante reseñar que el fichero se creó con la codificación ANSI que ofrece por defecto para no incurrir en problemas de caracteres raros. Lo vemos a continuación: fichero, script y resultado, y lo comentamos un poquito.

A la derecha del todo tenemos nuestro archivo z.txt con una serie de nombres y, tras los dos puntos, un número decimal. A la izquierda, tenemos el script, en formato de función definida por el usuario para ganar versatilidad. Mediante la función integrada input() solicitamos la introducción de un archivo (obviamente, z.txt). Justo a continuación, en 1. y 2., creamos sendas listas, la primera para almacenar los datos y la segunda para almacenar los decimales. Prescindimos de un creador de entorno (with open(...) as ...:) porque para el caso no nos interesa, y vamos a degüello con una variable, apertura, que almacenará la apertura del archivo. Recurrimos, entonces, a un bucle for/in para almacenar en nuestra lista de datos aquéllas líneas, y sólo aquéllas líneas, que cumplan con la condición de comenzar por X-DSPAM-Confidence:, y discriminando a todas las demás, cosa que hacemos en 3. con el condicional if.
Por fin (aunque en el script no he insertado un print() para ver el resultado en todo su esplendor), tenemos una lista de datos discriminada de la que extraer la información que queremos: los decimales que acompañan a cada línea después de los dos puntos. Para esto declaramos una variable, a, que almacenará el índice donde se localiza en cada cadena (línea) los dos puntos mediante el método str.index(substring) de las cadenas, como vemos en 4.. Y llegamos a la clave del asunto: las rebanadas (slices) que son las que nos sacarán del apuro.
Añadiremos a listadecimales, que es donde vamos a guardar los decimales, un trozo de cada item (la línea completa, recordemos). Este trozo estará a partir del índice de la substring ":" en adelante. Pero, si nos fijamos, pedimos que la función preconstruida eval() convierta a número el resultado que nos dé. ¿Por qué? Porque la devolución simple del trozo item[a+2:] nos devolvería para todos los casos la cadena siguiente: "decimal\n", por ejemplo, "4.53\n". Esto es así porque al guardar las líneas en la lista listadata, Python lo hace con su escape (salto de línea, \n adjuntado). De todas formas, en la página CREAR, ABRIR Y ESCRIBIR ARCHIVOS, quien quiera podrá consultar la posibilidad de que en la lista no se incluya el salto de línea para cada una.

ORDENAR TURNOS DE MANERA COHERENTE PASADOS COMO CADENAS.
En esta ocasión se trata de resolver un problemilla que nos puede surgir si tratamos de ordenar cadenas (strings), bien en sentido ascendente como descendente, y el asunto no nos cuadra. He escogido como ejemplo un ordenamiento de turnos. Por ejemplo, si tenemos tres turnos ("Primero", "Segundo", "Tercero") y los ordenáramos como strings para obtener un resultado como: "Primero: Daisy", "Segundo: Pato Donald", "Tercero: Minnie", el resultado sería, exactamente, el que acabamos de mostrar. Y este resultado sería coherente. ¿Por qué? Porque, casualmente, en castellano, cada primera letra de la cadena de los nombres de turno, "P", "S" y "T" permiten un ordenamiento correcto. ¿Pero y si añadimos un turno "Cuarto"? Tendríamos, por ejemplo, esta clasificación, digamos, hecha a mano: "Primero: Daisy", "Segundo: Pato Donald", "Tercero: Minnie", "Cuarto: Mickey Mouse". Pero si nosotros, como programadores, no accedemos a la clasificación y la manipulamos sino que sería el resultado de la ejecución de un programa y le pedimos a Python que nos ordene la lista, ¿cómo nos la mostraría? Así: "Cuarto: Mickey Mouse", "Primero: Daisy", "Segundo: Pato Donald", "Tercero: Minnie". Incoherente, ¿Verdad? ¿Cómo podríamos solucionar esto? Pues muy sencillo: como los números se ordenan siempre bien, asignemos un número a cada string (luego estamos hablando de un diccionario, lo que se denomina "hacer un mapeo") y, luego, utilicemos la cadena asociada a ese mismo número para establecer un ordenamiento correcto.
Vamos a verlo con un ejemplo:

En 1. tenemos una lista que nos ha arrojado una ejecución anterior, supongamos, ya con el orden adecuado. Declaramos a continuación una lista con el orden de los elementos de la lista de nombres anterior: para hacerlo, le pedimos que establezca un rango de números entre el 1 y el tamaño de la lista más 1, dado que la función integrada range() siempre comienza a contar desde 0, por lo que devolvería 3 como número final (0,1,2,3), cuando sabemos que siempre será una unidad superior (de manera natural, nunca se empieza a contar desde cero sino desde uno: si tenemos tres manzanas no contamos cero, una y dos, sino una, dos y tres). Esto nos devuelve una lista, num, de la forma siguiente: num = [1, 2, 3, 4]. Ya tenemos, pues, los numerales que determinan el orden real de cada elemento de la lista.
En 2. declaramos sendos diccionarios (mapas) inversos: en d los números enteros son las claves (keys) y las cadenas los valores (values), mientras que en contrad es a la inversa, las cadenas son las claves (keys) y los enteros los valores (values).
A través de la variable orden, en 3., declaramos un diccionario que asigna un número (posición) a cada nombre de la lista, mientras que en 4. declaramos un lista nueva, listanew, que almacenará los resultados de manipular el diccionario orden.
En 5. recurrimos a la magia de Python. Establecemos una estructura de bucle anidado de acuerdo a dos iterables, el primero, orden.keys(), donde el método keys() de los diccionarios y que aplicamos sobre orden, devuelve una lista (recordemos que no podemos iterar directamente sobre un diccionario porque sólo nos devuelve las claves pero no sus valores asociados) con sólo las claves, es decir, los enteros (posiciones). Ciertamente, podríamos haber pasado directamente la lista num, que ya contiene las mismas claves que hemos usado para construir el diccionario orden, pero haciéndolo así queremos mostrar que también es posible conseguir un resultado similar si en lugar de una lista de partida, contáramos sólo con el diccionario y tuviéramos que solucionar las cosas partiendo únicamente de él.
En el segundo bucle for/in creamos un segundo iterable, contrad.values(), esta vez con los valores asociados a cada entero usando para ello el método values() de los diccionarios y que nos sirve para obtener una lista de valores. Con la tercera línea implementamos un condicional en base a una equivalencia: cada vez que un "item" de la lista de enteros de orden.keys() es igual a un "ele" de la lista de números enteros de contrad.values(). De ser así, los "ele" (enteros) que cumplan esta condición se pasarán en la cuarta y última línea de la estructura de bucles anidados como los valores que pasamos al diccionario d a través del método get() para obtener los valores de éste último correspondientes, y almacenarlos en la variable listanew.
Finalmente, en 6. creamos una lista a través del método cremallera zip() que empareja cada elemento de listanew con los nombres originales de lista, devolviendo un resultado coherente.
Si desde el principio hubiéramos contado con un diccionario como éste: posiciones = {"Primero": "Daisy", "Segundo": "Pato Donald", "Tercero": "Minnie", "Cuarto": "Mickey Mouse"} nos basta, simplemente, con extraer sólo los valores del diccionario y guardarlos en un objeto tipo lista (listavalores = posiciones.values()), procediendo a continuación del mismo modo que mostramos en el ejemplo.


CUADRAR CANTIDAD DE DATOS EN EL EJE X Y EN EL EJE Y DE UNA GRÁFICA.
En esta ocasión se trata de cuadrar datos en sendas listas: una para el eje y (ordenadas) y la otra par el eje x (abscisas), de tal modo que la información, en el momento de graficarla, se exponga mejor, de forma más coherente y, visualmente, más completa, ordenada y atractiva. Debemos partir de la base que que casi todas las aplicaciones de Python que contamos, todas de terceros (Matplotlib, Bokeh, Reportlab (para documentos pdf), GooPyCharts, etc.) requieren que se les pase igual cantidad de datos para el eje y como para el eje x. A veces nos encontramos que tenemos pocos datos para mostrar una gráfica molona de verdad, y que nos vendría bien rellenar datos, tanto en el eje x como en el y, para que la cosa se vea mejor y más completa.
Imaginemos que tenemos una panadería que, por esto de la pandemia, sólo ha podido abrir tres días en un mes: el 7, el 17 y el 27 de Junio. Pues bien, ¿Como completar los datos, tanto con las cantidades vendidas como el número total de días del mes de Junio, 30 en total? Vamos a verlo:

Como vemos, el código no es nada complejo. En 1. tenemos una lista con los únicos días que hemos abierto en nuestro mes de Junio, que tiene treinta días, como Abril, Septiembre, el propio Junio o Noviembre (obviamente, podemos escoger cualquier otro mes con treinta y un días, o Febrero, con veintiocho o veintinueve, en los años bisiestos), y en 2., con panes, tenemos las cantidades de barras de pan vendidas en esos días. Justo a continuación, la variable lenmes contiene un entero que expresa el número total de días de Junio, 30.
A continuación, en 3., creamos una lista de enteros a la que llamamos mes, que empieza en uno y termina con el valor de lenmes más uno, con lo que obtendremos la lista de días que tiene el mes de junio y que sería, por ejemplo nuestro eje x (abscisas). Así de sencillo.
Ahora vamos a crear una lista para las cantidades. Lo primero que vamos a hacer, tal y como vemos en 4., es declarar una variable, listazeros, que va a tener la misma cantidad de ceros que días tiene Junio. Lo hacemos apoyándonos en la lista mes que tenemos ya construida mediante un bucle for/in. ¿Y por qué de ceros? Porque estos ceros representarán los días del mes que no hemos vendido nada por haber mantenido cerrada nuestra panadería. Así, sólo tendremos que modificar el valor 0 por la cantidad correspondiente (64, 121 y 51, según nuestra lista panes) de acuerdo a los días que sí hemos estado abiertos (7, 17 y 27, según la lista diasennumeros).
Para conseguir esto lo primero que tenemos que hacer es emparejar mediante la función integrada cremallera zip() los días que hemos abierto con sus correspondientes cantidades de pan vendidas. Para eso, en 5. declaramos la variable par a la que asignamos la siguiente expresión: list(zip(diasennumeros, panes)), que devuelve una lista con sendas 2-tuplas.
En 6. será donde consigamos nuestro propósito: mediante un bucle for/in iteramos por los elementos de la lista par de tal modo que en nuestra lista de 30 ceros (listazeros), aquél elemento cuyo índice coincida con el primer elemento de la tupla (el día) sea sustituido por el segundo elemento de la la tupla, la cantidad, con lo cual el 0 original, conforme el intérprete de Python itera sobre la lista, será sustituido paulatinamente por 64 en la posición/índice 7, 121 en la posición/índice 17 y, finalmente, 51, en la posición/índice 27.
Para acabar, declaramos una variable eje_y que almacenará los cambios que ha sufrido nuestra lista original listazeros. Y ya tenemos nuestro eje x (abscisas) con los treinta días del mes de Junio y que tenemos almacenados en la variable mes, y un número similar de datos para el eje y (ordenadas) con las cantidades correspondientes.



Para finalizar con este apartado y que, por cierto, os sugerimos que de vez en cuando echéis un vistazo por si añadimos alguna cosita nueva, os dejamos unos pocos enlaces para que podáis consultar en otros sitios web nuevos scripts igual de sencillos que, de seguro, os resolverán muchos problemas.
¡Saludos perrunos!
Como regalo de despedida nuestro en este apartado, un script divertido... o algo. ¡Probadlo!


ENLACES
- Microrrecursos de Python: microrrecursos.
- 10 snippets útiles: snippets.
- Scripts varios: scripts.
- Trucos Python: trucos.
Finalmente, una excelente página para obtener códigos (y manipularlos) basados en el uso de módulos de Python, para los "impacientes" que quieran aventurarse desde ya con la librería estándar de Python:
Tan sólo hacemos clic en los módulos que se nos muestran así como en otros que se nos mostrarán pulsando en los cuadraditos de la parte inferior a modo de páginas, y a consultar ejemplos como posesos... ¡Venga!...¡Hala!. Consultad los nombres en inglés porque su traducción al castellano podría resultar equivoca.

Gracias!
ResponderEliminarDe nada, Neto Saavedra. Saludos.
ResponderEliminarexcelente :)
ResponderEliminarMuchas gracias. Saludos.
ResponderEliminarMuy útil. Felicidades
ResponderEliminarMuchas gracias. Saludos.
ResponderEliminar