|
| MUSGO SOBRE LAS PIEDRAS Y HOJARASCA EN EL SOTOBOSQUE DEL MONTE DEL AGUA, NOROESTE DE TENERIFE. |
Esta nueva función de Python nos va a caer simpática. Ya veremos que sí. Se trata de una función integrada que, como su nombre sugiere, determina un rango, delimita un "terreno", un espacio, una porción de algo, por ejemplo, de una lista donde aplicamos una expresión concreta. Precisamente por eso, la función range() incorpora como argumentos un índice de inicio y un índice final que sirve, como nos podemos imaginar, para encapsular un espacio específico a partir de otro dado, casi lo mismo que consiguen las rebanadas o slices con una string, por ejemplo.

Una FUNCIÓN INTEGRADA puede definirse como aquélla que no requiere ser llamada o invocada desde módulo alguno, en tanto que es accesible por defecto, esto es, que su carga y uso se realiza automáticamente lo que las emparenta con las funciones preconstruidas built-in.
Tengamos en cuenta que la función range() no funciona por sí sola sino que que debe ir asociada a un bucle en for/in para poder desplegar todos sus encantos. Veamos un ejemplo:
Tengamos en cuenta que la función range() no funciona por sí sola sino que que debe ir asociada a un bucle en for/in para poder desplegar todos sus encantos. Veamos un ejemplo:

En 1. construimos un objeto de tipo de dato list para albergar una colección de números enteros.
Ya en 2. establecemos el bucle for/in para la lista. Hagamos hincapié en que no escribimos la fórmula incluyendo el nombre de la lista, lista_de_números, sino que escribimos directamente la función range(), dado que el incluirla en la fórmula como 'for ítem in lista_de_números in range(5, 10):', por ejemplo, lanzaría una excepción advirtiéndonos de un error de tipo booleano. Esto se debe a que presentada la lista, Python interpreta que el segundo 'in' es un operador de verificación o pertenencia sobre la función range(), indagando sobre sí la lista está presente en range() o no lo que, como podemos deducir, no tiene sentido gramatical.
En 3. Python nos devuelve el resultado iterado, en formato de columna, que muestra la devolución por defecto de la función range() como un ITERADOR o ITERABLE, en tanto que la función permite iterar por todos y cada uno de los elementos que componen la acotación, de principio a fin y de izquierda a derecha. Fijémonos en que al igual que sucede con las rebanadas, el índice de inicio se incluye en el resultado pero el índice final es n-1. Tengámoslo presente.
En 4. añadimos un entero 'z' para que Python nos devuelva el resultado de dos en dos, con lo que hemos obtenido los impares que van del 1 al 10.
En 5. añadimos un entero 'z' para que Python nos devuelva el resultado de dos en dos, con lo que hemos obtenido los pares que van del 10 al 21.
Ya en 2. establecemos el bucle for/in para la lista. Hagamos hincapié en que no escribimos la fórmula incluyendo el nombre de la lista, lista_de_números, sino que escribimos directamente la función range(), dado que el incluirla en la fórmula como 'for ítem in lista_de_números in range(5, 10):', por ejemplo, lanzaría una excepción advirtiéndonos de un error de tipo booleano. Esto se debe a que presentada la lista, Python interpreta que el segundo 'in' es un operador de verificación o pertenencia sobre la función range(), indagando sobre sí la lista está presente en range() o no lo que, como podemos deducir, no tiene sentido gramatical.
En 3. Python nos devuelve el resultado iterado, en formato de columna, que muestra la devolución por defecto de la función range() como un ITERADOR o ITERABLE, en tanto que la función permite iterar por todos y cada uno de los elementos que componen la acotación, de principio a fin y de izquierda a derecha. Fijémonos en que al igual que sucede con las rebanadas, el índice de inicio se incluye en el resultado pero el índice final es n-1. Tengámoslo presente.
En 4. añadimos un entero 'z' para que Python nos devuelva el resultado de dos en dos, con lo que hemos obtenido los impares que van del 1 al 10.
En 5. añadimos un entero 'z' para que Python nos devuelva el resultado de dos en dos, con lo que hemos obtenido los pares que van del 10 al 21.
Contamos con una sintaxis singular aprovechando la cualidad de la función range() de recorrer una lista completa establecidos un índice de inicio y otro final, que nos permite realizar una acción sobre todos y cada uno de los ítems de una lista dada. Para hacerlo no tenemos más que pasar como argumento de la función otra función, una de nuestras viejas conocidas. ¿Cuál? La función len() que, repasemos, devuelve la longitud de una colección de datos. Veámoslo en el ejemplo que sigue:
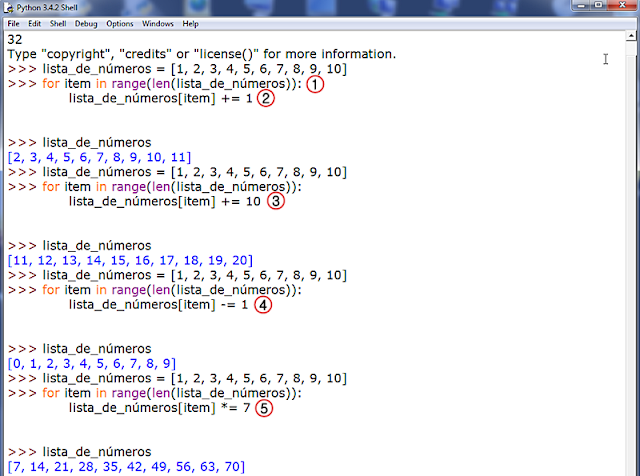

En 1., una vez tenemos la lista, introducimos la sintaxis anteriormente mencionada.
A continuación, en 2., establecemos una llamada a los índices. Al colocar 'item' de la lista estamos diciendo que lo que vayamos a hacer se va a aplicar a todos y a cada uno de los elementos de la lista, gracias a que hemos pasado advirtiendo de ello la función len() como argumento de range(). ¿Y qué es lo que le vamos a hacer a cada uno de estos elementos? Pues lo que hemos escrito justo a la derecha: un operador de incremento (se utiliza muy a menudo en programación) que sumará 1 a cada ítem, como podemos comprobar en la devolución.
En 3. optamos por incrementar en 10. En 4. por restar o sustraer 1. Y en 5. por multiplicar por 7 cada elemento de nuestra lista. Con este último ejemplo, podríamos construir perfectamente una sencilla tabla de multiplicar.
Fijémonos a continuación en el siguiente ejemplo:

A continuación, en 2., establecemos una llamada a los índices. Al colocar 'item' de la lista estamos diciendo que lo que vayamos a hacer se va a aplicar a todos y a cada uno de los elementos de la lista, gracias a que hemos pasado advirtiendo de ello la función len() como argumento de range(). ¿Y qué es lo que le vamos a hacer a cada uno de estos elementos? Pues lo que hemos escrito justo a la derecha: un operador de incremento (se utiliza muy a menudo en programación) que sumará 1 a cada ítem, como podemos comprobar en la devolución.
En 3. optamos por incrementar en 10. En 4. por restar o sustraer 1. Y en 5. por multiplicar por 7 cada elemento de nuestra lista. Con este último ejemplo, podríamos construir perfectamente una sencilla tabla de multiplicar.
 |
| FLOR DE LA CERRAJA, PLANTA CARACTERÍSTICA DEL BOSQUE HÚMEDO DE TENERIFE. |
Fijémonos a continuación en el siguiente ejemplo:

Observemos que en 1., como no nos es posible efectuar la operación de incremento de 1 para todos y cada uno de los ítems, ya que se nos lanza una excepción que nos advierte que el índice que hemos pasado, x, está fuera de rango.
En 2. planteamos la alternativa lógica a la propuesta de sintaxis que hemos visto más arriba con len(), y que pasa por proponer el range() completo, del primero al último de los índices, o lo que es lo mismo:
range(índice de inicio, índice final) = len(lista)
En 2. planteamos la alternativa lógica a la propuesta de sintaxis que hemos visto más arriba con len(), y que pasa por proponer el range() completo, del primero al último de los índices, o lo que es lo mismo:
range(índice de inicio, índice final) = len(lista)
Percatémonos de que para que el asunto funcione, le hemos pasado como índice de inicio el número inmediatamente anterior (o menor) que el primero de nuestra lista que, siendo 1, corresponde al 0; mientras que como índice final hemos puesto el último elemento de la lista, 10.
En 3. vemos cómo podemos llevar a cabo la acción seleccionada sobre un grupo de elementos concreto recurriendo al acotamiento que pasamos como argumento de range().

En 3. vemos cómo podemos llevar a cabo la acción seleccionada sobre un grupo de elementos concreto recurriendo al acotamiento que pasamos como argumento de range().
A CONTINUACIÓN MOSTRAMOS UNA TABLA QUE NOS SERÁ SUMAMENTE ÚTIL PARA REALIZAR OPERACIONES ARITMÉTICAS APLICABLES AL TOTAL DE ÍTEMS DE UNA COLECCIÓN.

Es importante tener en cuenta, como acabamos de ver, la dependencia singular, si podemos decirlo así, entre las listas y el bucle for/in para realizar un alto número de operaciones. entraremos en ello con mucha más profundidad cuando tratemos el bucle for/in.
Existe otra forma...mmm...¿cómo decirlo?... más "amable", "elegante" y que consiste en aplicarle a una lista dada un recorrido con la función range() y es recurriendo, de nuevo, a las técnicas de troceado. Pero eso sí, con una rebanada un tanto especial que pasa por incluir dos veces los dos puntos: [x::y], donde x es el índice de inicio e y el valor que se le suma a x dentro de len() de una lista dada. Miremos el ejemplo:

En 1. construimos un bloque de código cuya sintaxis ya conocemos y que consiste en aplicarle a una lista dada un recorrido con la función range() (hubiéramos podido sustituir los datos que pasamos como argumentos por len()) de principio a fin y contando de dos en dos. La aplicación de esta función nos devuelve un resultado iterado de ítems de 1 al 9.
Pero en 2. tenemos que la lista original ha sido transformada en una nueva lista que contiene los mismos valores numéricos que obtuvimos en 1.
En 3. creamos una nueva lista 'k' conformada por strings. Sin embargo, al aplicarle la función iteradora range() obtenemos un resultado similar a 1. ¿Por qué sucede esto? Porque iterará sólo sus índices y no los valores que representan. Para conseguirlo tenemos que escribir:

Finalmente, en 4. observamos cómo obtenemos una nueva lista 'k' con los string que buscábamos.
Terminamos esta entrada dedicada a la función range() aportando unos pocos ejemplos más que nos permitirán comprender mejor las posibilidades y la plasticidad de esta función integrada de Python.



Podríamos necesitar que, en vez de contar hacia a delante, esto es, por ejemplo, de 1 a 10, de menor a mayor, hacerlo al revés, es decir, de 10 a 1, de mayor a menor. Para conseguirlo, tan sólo necesitamos dos cosas: pasar en negativo el primer valor del argumento (nos basta con añadir delante el signo menos, -), que es desde donde empezará a contar, mientras que el segundo lo podemos dejar también con el signo menos, -, o sin signo dependiendo hasta dónde queramos contar; e incluir la función nativa abs(), de absolute, que como su nombre indica, nos devuelve valores absolutos, sin signo aplicado sobre cada elemento del iterable. Vamos a verlo con ejemplos:

Para finalizar, tengamos presente que la función range() SÓLO admite como argumentos números enteros. No admite ningún otro tipo de dato distinto. De no ser así se lanzará una excepción, un error, desde el intérprete de Python.
Existe otra forma...mmm...¿cómo decirlo?... más "amable", "elegante" y que consiste en aplicarle a una lista dada un recorrido con la función range() y es recurriendo, de nuevo, a las técnicas de troceado. Pero eso sí, con una rebanada un tanto especial que pasa por incluir dos veces los dos puntos: [x::y], donde x es el índice de inicio e y el valor que se le suma a x dentro de len() de una lista dada. Miremos el ejemplo:

En 1. construimos un bloque de código cuya sintaxis ya conocemos y que consiste en aplicarle a una lista dada un recorrido con la función range() (hubiéramos podido sustituir los datos que pasamos como argumentos por len()) de principio a fin y contando de dos en dos. La aplicación de esta función nos devuelve un resultado iterado de ítems de 1 al 9.
Pero en 2. tenemos que la lista original ha sido transformada en una nueva lista que contiene los mismos valores numéricos que obtuvimos en 1.
En 3. creamos una nueva lista 'k' conformada por strings. Sin embargo, al aplicarle la función iteradora range() obtenemos un resultado similar a 1. ¿Por qué sucede esto? Porque iterará sólo sus índices y no los valores que representan. Para conseguirlo tenemos que escribir:

Finalmente, en 4. observamos cómo obtenemos una nueva lista 'k' con los string que buscábamos.
Terminamos esta entrada dedicada a la función range() aportando unos pocos ejemplos más que nos permitirán comprender mejor las posibilidades y la plasticidad de esta función integrada de Python.


Podríamos necesitar que, en vez de contar hacia a delante, esto es, por ejemplo, de 1 a 10, de menor a mayor, hacerlo al revés, es decir, de 10 a 1, de mayor a menor. Para conseguirlo, tan sólo necesitamos dos cosas: pasar en negativo el primer valor del argumento (nos basta con añadir delante el signo menos, -), que es desde donde empezará a contar, mientras que el segundo lo podemos dejar también con el signo menos, -, o sin signo dependiendo hasta dónde queramos contar; e incluir la función nativa abs(), de absolute, que como su nombre indica, nos devuelve valores absolutos, sin signo aplicado sobre cada elemento del iterable. Vamos a verlo con ejemplos:

Para finalizar, tengamos presente que la función range() SÓLO admite como argumentos números enteros. No admite ningún otro tipo de dato distinto. De no ser así se lanzará una excepción, un error, desde el intérprete de Python.
 |
| AMANECER SOBRE EL TEIDE, CON SU SOMBRA PROYECTÁNDOSE SOBRE EL PICO VIEJO Y TODO A LO LARGO DE LA ISLA. |